AI 기술의 성공적인 적용을 위해 데이터와 도메인 전문가의 협력이 필수적이다. AI 기술이 단순히 기술로만 존재하는 것이 아니라, 산업별 맞춤형 솔루션으로 발전하기 위해서는 각 분야의 전문 지식과 데이터를 통합하는 것이 중요하다.
C. 핵심 내용
2월 1일 글로벌 컨퍼런스 'AI 서울 2024'는 AI 기술의 산업 적용과 도메인 전문가의 협력, 클라우드 플랫폼의 역할, 데이터 중심 조직의 필요성 등을 다루며, AI의 미래 방향성을 제시했다.
1. AI의 핵심과 도메인 전문가의 중요성: 이현규 정보통신기획평가원(IITP) PM 그룹 민간전문가는 AI 기술이 단순한 기능일 뿐, 산업에 적용하기 위해서는 도메인 전문가의 역할이 중요하다고 강조했다. 현재 AI 활용률은 2.7%로 낮으며, 이는 기술에 대한 과도한 기대와 기존 방식에 대한 집착 때문이라고 지적했다.
2. 기술 활용의 시기와 데이터의 중요성: AI 기술은 적절한 시점에 사용해야 성공할 수 있으며, 데이터의 중요성을 간과해서는 안 된다고 말했다. 알고리즘 전문가와 도메인 전문가의 협력이 AI의 일상화와 대중화에 필수적이라고 강조했다.
3. AI와 클라우드의 역할: 정태일 구글 클라우드 코리아 커스터머 엔지니어는 구글 클라우드가 AI 활용을 위한 빅데이터 수집과 활용을 지원하며, 온프레미스 환경 없이도 AI 환경을 구축할 수 있다고 설명했다. 주요 제품으로는 빅쿼리와 버텍스 AI를 소개했다.
4. 생성형 AI와 데이터 중심 조직: 김기병 아마존웹서비스(AWS)코리아 매니저는 생성형 AI 시장에서 데이터 활용과 기업 특화 애플리케이션의 중요성을 강조했다. 데이터 중심 조직으로의 변화가 필요하며, 이를 통해 프로토타이핑과 인프라 비용 문제를 해결해야 한다고 말했다.
5. AI 서비스 사례: 클로바 케어콜: 옥상훈 네이버클라우드 AI SaaS 비즈니스 리더는 고독사 방지를 위한 AI 전화 서비스인 '클로바 케어콜'을 소개했다. 초기 챗봇 기반에서 초거대 AI로 발전하여 대화의 자연스러움과 업무 효율성을 높였으며, 향후 건강 관리와 IoT 디바이스와의 결합을 계획하고 있다고 밝혔다.
D. 도메인과 AI 전문가, 그리고 나
건축 및 도시계획 분야에서 데이터 분석가가 되기 위한 내용을 AI에게 물어본 대답을 정리하면 아래와 같다.
필요한 능력 1.데이터 분석 기술 - 통계학 및 수학적 기초: 데이터 분석의 기초 지식 - 프로그래밍 언어: Python, R, SQL 등 데이터 처리 및 분석을 위한 언어 이해
2. GIS(지리정보시스템) 기술
- GIS 소프트웨어(ArcGIS, QGIS) 활용 능력.
3. 데이터 시각화 - Tableau, Power BI 등의 도구를 사용하여 분석 결과 전달.
4.문제 해결 능력 - 복잡한 문제를 정의하고 데이터 기반 해결책 제시.
5. 커뮤니케이션 능력 - 분석 결과를 이해하기 쉽게 설명하고 다양한 이해관계자와 소통.
필요한 자격증 1.데이터 분석 관련 자격증 - Google Data Analytics Professional Certificate - Microsoft Certified: Data Analyst Associate
2.GIS 관련 자격증 - Esri Technical Certification - GIS Professional (GISP)
3. 통계 및 데이터 과학 관련 자격증 - Certified Analytics Professional (CAP) - SAS Certified Data Scientist
추가적인 학습 및 경험 - 학위: 도시계획, 건축학, 데이터 과학, 통계학 등 관련 분야의 학사 또는 석사 학위
def solution(arr1, arr2):
for i in range(len(arr1)):
for j in range(len(arr1[0])):
arr1[i][j] += arr2[i][j]
return arr1
B. 다른 사람 풀이
- numpy를 활용한 풀이
- 비슷하지만 다른 풀이로, numpy, pandas 문법에도 익숙해져야 할 것 같아 기록해둔다.
import numpy as np
def sumMatrix(A,B):
A_np = np.array(A)
B_np = np.array(B)
result = A_np + B_np
return result.tolist()
# return [[c + d for c, d in zip(a, b)] for a, b, in zip(A, B)]
- 가장 마음에 든 풀이이다.
- 나도 처음에 zip() 함수를 사용해보고 싶었는데, 공백만 출력되었다.
- 함수를 어떻게 하면 유연하게 적용할 수 있을까 고민해봤지만, 답은 역시 하나다.
- 더 많은 문제를 풀어보고, 더 많은 코드를 보고, 다시 내 지식으로 만들기 위해 애써야 한다.
def sumMatrix(A,B):
answer = [[c + d for c, d in zip(a,b)] for a, b in zip(A,B)]
return answer
graph = df.value_counts(['Age'])
graph.plot(kind= 'bar', figsize=(10,10),stacked = False, color = colors)
# 제목과 레이블 추가
plt.title('Age')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.xticks(rotation=0, ha='center')
# x축 ticks 설정 (명명하기)
new_labels = ['20-35', '12-20', '35-60'] # 새로운 레이블
plt.xticks(ticks=range(len(new_labels)), labels=new_labels, rotation=0, ha='center')
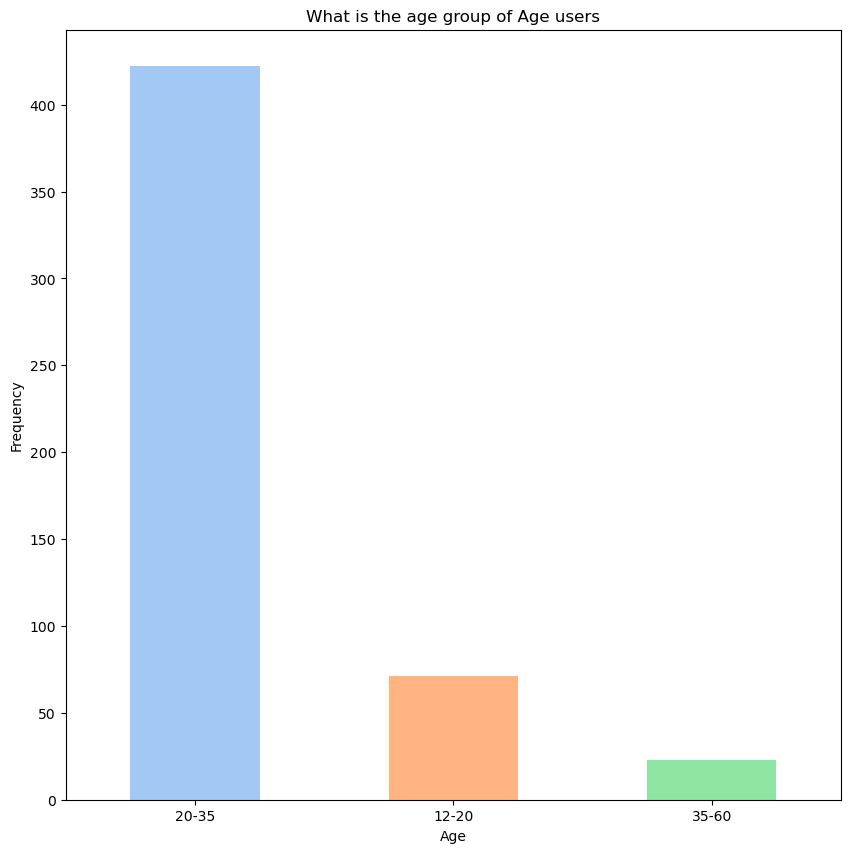
1) Age, Gender
사용자 연령대
사용자 성별
- 20~35세 사이의 주사용자이며, 여성 비율이 압도적으로 많다.
2) Genre, Time
음악 장르 선호도
음악 감상 시간
- Melody 장르를 압도적으로 선호한다.
- Pop 과 Classical 장르도 상대적으로 높은 빈도를 보였으나 Melody에 비해 현저히 적은 빈도를 나타낸다.
- 주로 밤에 스포티파이를 이용해 음악을 감상한다.
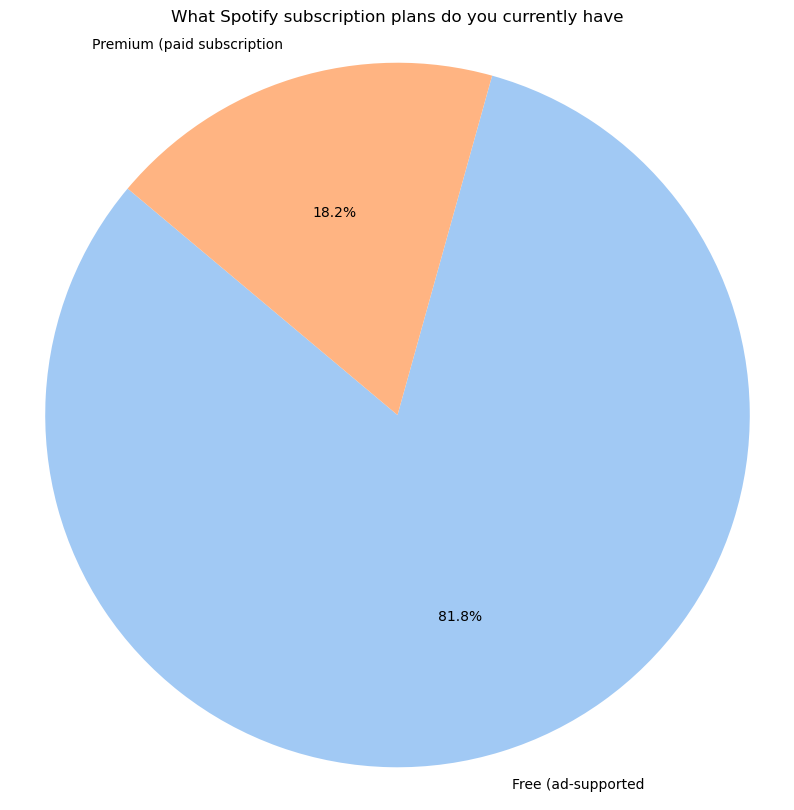
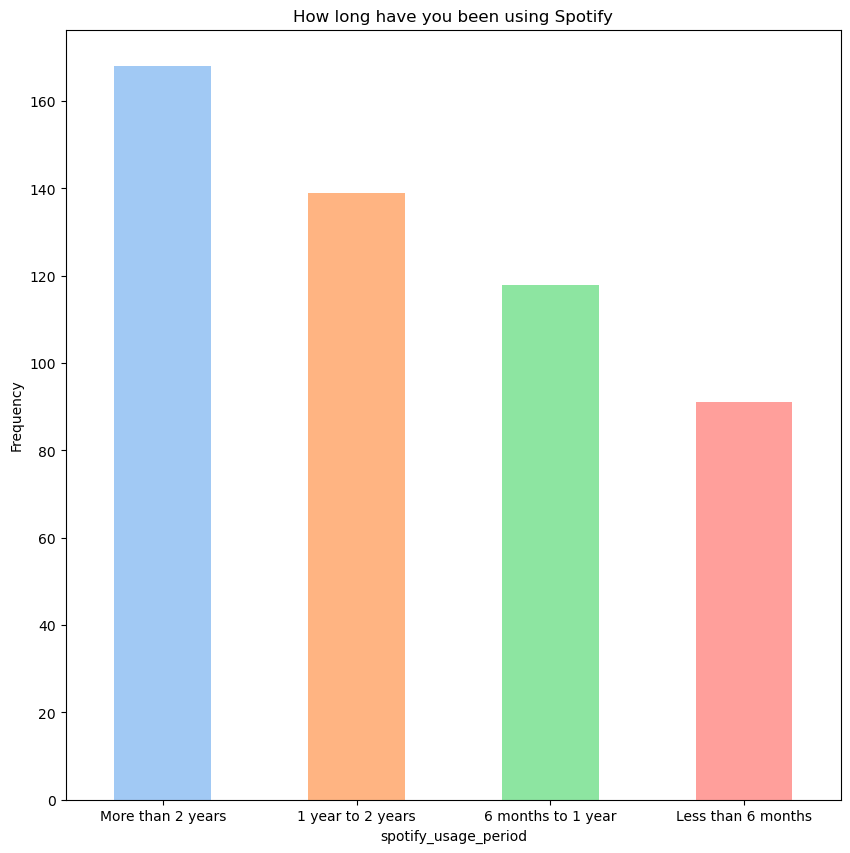
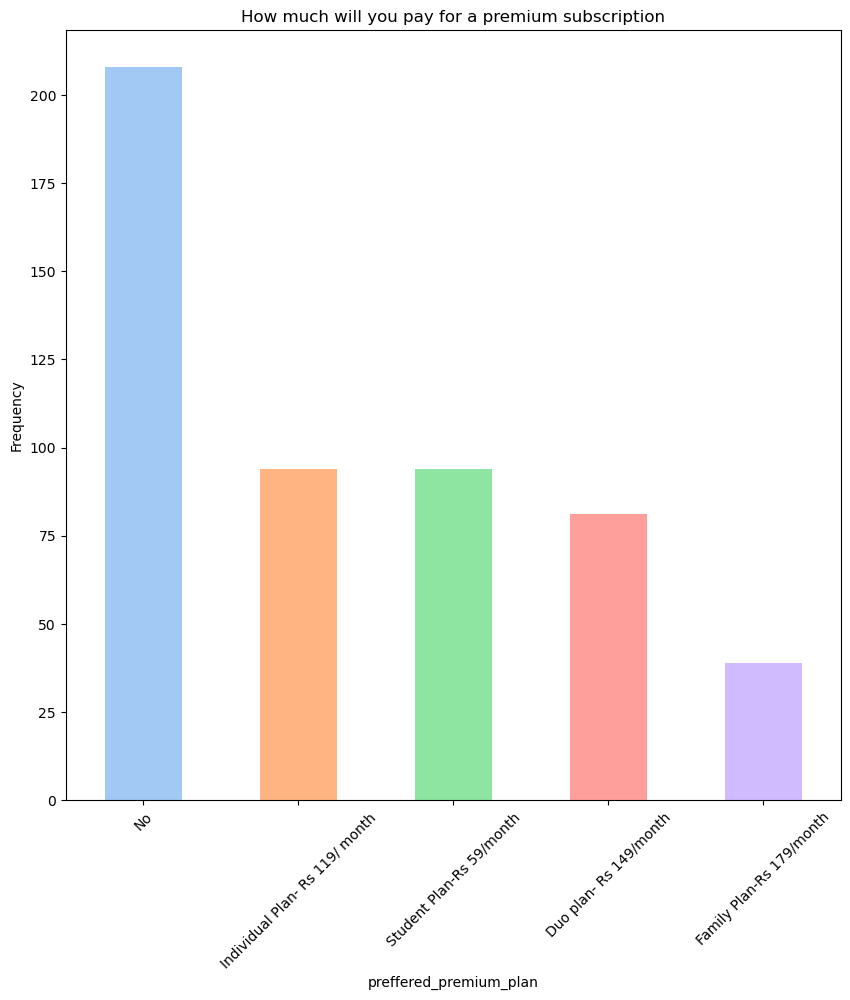
3) About Spotify Subscription
현재 스포티파이 구독 방법
스포티파이 구독 기간
추후 구독 의사
구독료 지불 의사
- 무료 사용자(81.8%)가 무료(광고 지원)버전을 사용하고 있으며, 프리미어 사용자는 18.2%이다.
- '2년 이상' 사용한 사용자 수가 가장 많다.
- 응답자의 64.1%가 프리미엄 구독을 계속하지 않겠다고 응답하였으며, 35.9%가 계속 구독할 의향이 있다 답하였다.
- 프리미엄 구독을 원하지 않는 사용자가 가장 많았고, 그 뒤를 이어 개인 플랜과 학생 플랜이 비슷한 빈도로 선택되었다.
4) User Preference
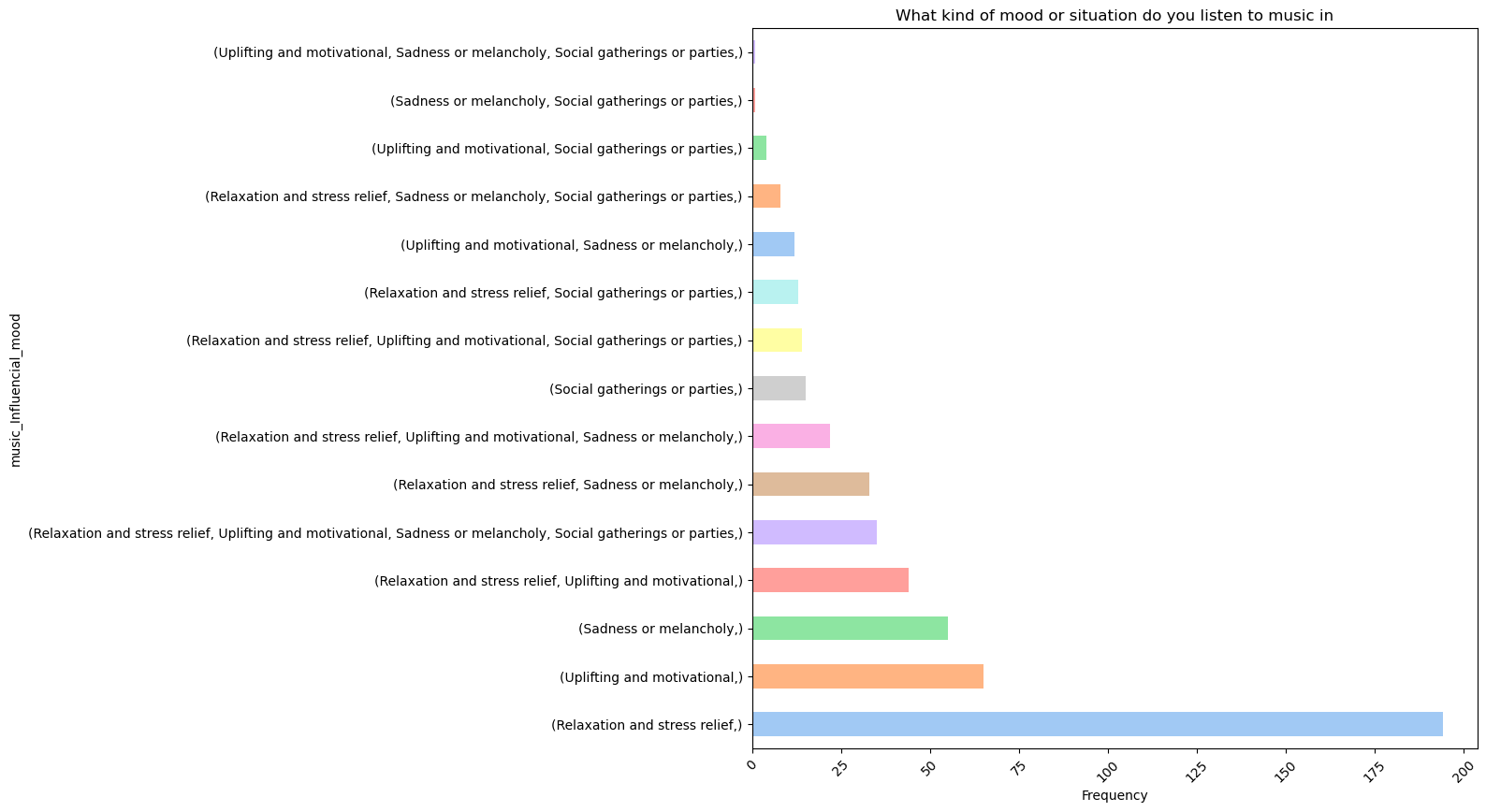
음악 감상 분위기
음악 감상 시 사용 장치
음악 듣는 상황
추천 음악 만족도
- 'Relaxation and stree relief' 기분일 때 Spotify 이용에 가장 큰 선호도를 보인다. 이 감정일 때 다양한 음악 장르가 인기있다.
- 'Uplifting and motivational' 기분일 때 또한 높은 선호도를 나타낸다.
- '스마트폰'으로 Spotify를 이용하는 사용자가 가장 많다. '컴퓨터 또는 노트북'과 '스마트 스피커 또는 음성 비서'가 그 뒤를 따라온다.
- 여행 중 또는 여가 시간에 음악을 듣는 비율이 가장 높다.
- 음악 추천 점수는 3.0에서 4.0 사이에 집중되어 있다.
4) Information
사용자 연령별 선호 장르
시간대별 감상 장르
상황별 음악 장르 선택
사용자 연령별 시간대별 감상 장르
음악 플레이스트 선정 방식
장르별 음악 플레이스트 선정 방법
구독 유형별 음악 추천 평균 점수
시간대별 음악 감상 장치
- 대부분의 사람들이 음악을 밤에 가장 많이 듣는다.
- 20~35세 연령대에서 선호하는 음악 장르는 다양하다.
- 20~35세 연령대는 밤 시간대에 K-POP 및 Melody 장르에서 가장 많은 수치를 기록하고 있고, 다른 시간대 보다 더 다양한 장르의 음악이 소비한다.
- 다양한 장르가 야간에 청취되는 비율이 높아, 사용자의 음악 취향의 폭이 넓다는 점을 나타난다.
- Kpop장르는 Melody를 통해 새로운 음악을 가장 많이 발견되고 있다.
- Pop장르 역시 Playlist 와 Recommendations 를 통해 많이 발견되고 있다.
- 'Smartphone'을 가장 많이 사용하며, 특히 밤 시간대의 청취량이 높다.
B. 인사이트
음악소비패턴과 사용자 선호도에 대한 5가지 인사이트를 도출해낼 수 있다.
첫째, 연령대와 음악장르 선호에 대한 분석 결과, 20~35세 연령대에서 Kpop과 Melody 장르에 대한 선호도가 특히 두드러졌다. 이들은 다양한 음악장르에서 높은 선호도를 보이며, 주로 밤 시간대에 음악을 소비하는 경향이 있다. 이는 일이나 학업을 마친 후 여가 시간에 음악을 듣고자 하는 욕구와 관련이 있는 것으로 보인다. 반면 12~20세와 35~60세 연령대는 상대적으로 낮은 선호도를 보이며, 특정 장르에 대한 선호가 분산되어 있는 경향이 있다. 마케팅 전략이나 콘텐츠 개발 시 20~35세 사용자를 주요 타겟으로 삼는 것이 중요하다는 것을 시사한다.
둘째, Spotify 사용기기에 대한 분석 결과, 스마트폰이 300회 이상으로 가장 많은 선택을 받았다. 이는 사용자들이 언제 어디서든 쉽게 음악을 청취할 수 있는 환경을 제공하고 있음을 나타낸다. 특히 젊은 세대는 이동 중에도 스마트폰을 통해 음악을 소비하며, Kpop과 트렌딩 송이 가장 인기 있는 자리로 자리 잡고 있다.
셋째, 구독계획에 대한 분석에서는 81.8%의 사용자가 무료(광고 지원) 버전을 사용하고 있으며, 프리미어 사용자는 18.2%에 불과하다는 결과가 나타났다. 이는 광고가 포함된 무료 서비스 대다수가 사용자에게 선호되고 있음을 보여준다. 많은 사용자가 프리미엄 서비스에 대한 필요성을 느끼지 못하고 있으며, 사용자 경험을 개선하고 프리미엄 서비스의 가치를 높이기 윟나 추가적인 조치가 필요하다. 이를 위해 가격, 필요성, 기능 등을 고려한 사용자 의견 조사 등이 추가적으로 진행되어야 하며, 소비자들이 프리미엄 서비스로 전환하도록 유도하는 다양한 프로모션 전략과 혜택 제공이 있어야 한다.
넷째, 사용자는 주로 스트레스 해소와 긴장감 완화를 위해 음악을 듣는 경향이 있으며, 이는 긍정적인 기분을 유도하는 음악 장르를 강조하는 마케팅 전량이 효과적일 수 있음을 시사한다. 편안한 음악이나 명상 음악을 추천하는 켐페인은 사용자들이 더 많은 음악을 소비하게 할 가능성이 높다. 현대 사회에서 스트레스가 증가하는 사회 분위기 속 음악이 사람들에게 힐링의 역할을 할 수 있는 기회를 마련하는 것이 중요하다.
마지막으로, 프리미엄 지속 의향에 대한 분석에 따르면 응답자의 64.1%가 프리미엄 구독을 계속하지 않겠다고 응답하였다. 이는 고객 이탈의 위험 신호로, 추가적인 기능이나 혜택을 제공하여 사용자 만족도를 높이는 것이 중요하다. 독점 콘텐츠 제공, 사용자 맞춤형 추천 시스템 등이 이에 도움이 될 수 있다. 주 소비층이 소셜미디어 사회에 민감한 20~35세라는 것은 감안할 때, 앱 사용자간의 네트워크를 강화하고, 그들을 위한 차별화된 콘덴츠를 제공하는 것이 필요하다. 인기 아티스타의 라이브 공연 재생, 독점 인터뷰 등을 앱 전용으로 제공하는 방법이 있다. 소비자들은 독점 콘텐츠에 높은 가치를 두는 경향성이 있으므로 앱 활용도가 증가할 것이고, 스마트폰앱에서만 제공되는 콘텐츠는 사용자 충성도를 높이는데 기여할 것이다.
또한 챌린지 콘텐츠는 사용자 참여를 유도하고 자연스러운 마케팅 효과를 창출하는데 중요한 역할을 할 수 있다. 유명 인플루언서들이 참여할 경우, 그 효과는 더 거대해질 것이다. 사용자들이 공유한 콘텐츠는 타인에게 영향을 미치고 스포티파이만의 새로운 커뮤니티를 형성할 수 있는 기회를 제공할 것이다. 정적인 챌린지에서부터 노래, 춤 등의 동적인 챌린지까지 다양한 콘텐츠를 제공함으로써, 사용자들은 자신의 음악 청취 순간을 공유하고 더 많은 상호작용을 할 수 있다.
C. 결론
해당 분석은 Spotify의 음악 소비 패턴과 사용자 선호도를 이해하는데 중요한 기초자료가 될 것이다. 특히, 사용자 참여를 중심으로 한 챌린지 콘텐츠는 Spotify가 음악 소비의 새로운 패러다임을 선도하는데 중요한 기여를 할 것으로 기대된다. 젊은 세대의 다양한 음악 장르 선호와 스마트폰 사용의 용이함을 바탕으로, Spotify 사용자 간의 커뮤니티 형성을 촉진하고 자연스러운 마케팅 효과를 누릴 수 있다.
앞으로 지속적인 데이터 분석과 소비자 피드백 반영을 통해 유입 고객과 충성 고객의 비율을 높이고 이들의 이탈 비율이 줄여 나가는 것이 필요하다.
D. 여담
스포티파이는 이미 사용자추천 시스템이 매우 잘되어 있는 플랫폼으로 알고 있다. 한국에서 이들이 제대로 된 성과를 내지못한다는 것은 사용자 추천 시스템만의 문제가 아닐 것이다. 전 세계적으로 보았을 때 Spotify는 세계 1위 음악 플랫폼이다. 그렇다면 한국에서는 왜이리 주춤하고 있는 것일까. 필자는 멜론 등 한국에서 음악 플랫폼이 생성되기 시작할 때 함께 시작하지 못했기 때문이라 생각한다. 음악 플랫폼은 마치 은행과도 같다. 소비자들이 플랫폼을 쉽사리 바꾸지 못하고, 매우 사용하기 불편해질 때야 비로소 사용자가 움직이기 때문이다. 나도 여러번 음악 플랫폼을 바꾸어 보았지만, 내 취향에 맞는 음악들로 플레이리스트를 만들 때까지 꽤 많은 에너지를 쏟아야 했다. 이미 대부분의 음악 플랫폼은 이미 사용자 취향에 맞는 추천 시스템이 그들을 너무 잘 알기 때문에, 새 플랫폼에 내 정보를 주고 기존 사용하던 플랫폼과 비슷한 수준의 서비스를 제공받기 위해서는 줠대적 시간이 필요하다. 이 사이 사용자는 이 시간과 노력을 들여 플랫폼을 옮겨야 하는가에 대한 의문이 들 수 있고, 다시 한 번 플랫폼 변경에 대해 저울질할 것이다.
이때 스포티파이는 한국 유저들을 사로잡기 위한 매력적인 포인트가 아쉽게도 불충분하다. 멜론과 같이 아티스트들과 독점 컨텐츠, 콘서트 표 매매 등의 콘텐츠들이 있는 것도 아니며, youtube music 과 같이 프리미엄 구독을 하면 광고로 끊김 없이 영상과 음악 모두 즐길 수 있다는 유혹적인 제안도 없다.
스포티파이가 아무리 사용자 추천 시스템이 잘 되어 있다고 하더라도 사용자가 느끼기에 국내 기존의 플랫폼에서도 거의 비슷한 수준의 서비스를 제공하고 있다면 스포티파이는 한국에서 살아남기 위한 새로운 모험을 떠나야 할 것으로 보인다.
SELECT
C.CAR_ID,
C.CAR_TYPE,
FLOOR((C.DAILY_FEE * (1 - P.DISCOUNT_RATE / 100)) * 30) AS FEE
FROM
CAR_RENTAL_COMPANY_CAR C
JOIN
CAR_RENTAL_COMPANY_DISCOUNT_PLAN P ON C.CAR_TYPE = P.CAR_TYPE
WHERE
C.CAR_TYPE IN ('세단', 'SUV')
AND P.DURATION_TYPE = '30일 이상'
AND NOT EXISTS (
SELECT CAR_ID
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY H
WHERE H.CAR_ID = C.CAR_ID
AND (
(H.START_DATE <= '2022-11-30' AND H.END_DATE >= '2022-11-01')
)
)
HAVING
FEE >= 500000 AND FEE < 2000000
ORDER BY
FEE DESC,
C.CAR_TYPE ASC,
C.CAR_ID DESC
머신러닝은 데이터를 분석하고 학습하여 예측하는 기술로, 지도학습, 비지도 학습, 강화학습으로 분류한다. 개발 프로세스는 데이터 수집과 전처리, 모델 학습과 평가, 모델 배포와 유지보수로 구성한다. 추천 시스템, 이상 탐지, 자연어 처리, 이미지 인식 등 다양한 분야에서 활용한다.
C. 핵심포인트
머신러닝 정의: 알고리즘을 이용해 데이터 분석 및 그 결과를 스스로 학습하여 판단과 예측을 하는 기술.
1. 인공지능 > 머신러닝 > 딥러닝
- 인공지능(AI): 인간의 지능을 모방하는 기술. - 머신러닝(ML): AI 구현 방법. - 딥러닝(DL): 인공신경망을 기반으로 한 ML의 한 종류. 대규모 데이터 처리, 이미지 및 음성 인식에 주로 사용된다.
2. 머신러닝의 분류
- 지도학습: 레이블이 있는 데이터를 사용하여 모델 학습 (예: 분류, 회귀). - 비지도 학습: 레이블이 없는 데이터로 구조나 패턴을 발견 (예: 클러스터링, 차원 축소). - 강화학습: 환경과 상호작용하며 보상을 최대화하는 방식.
3. 머신러닝 개발 프로세스
1) 데이터 수집과 전처리: 데이터 분할, 결측값 처리, 이상치 제거. 2) 모델 선택 및 학습: 데이터 특성에 맞는 알고리즘 선택 (예: 선형회귀, 의사결정나무). 3) 모델 평가 및 검증: 분류 문제는 정확도, 정밀도; 회귀 문제는 평균제곱오차 등. 4) 모델 배포와 유지보수: 검증된 모델 배포, 모니터링, 업데이트.
4. 머신러닝 활용 사례
- 추천 시스템 개발. - 이상 탐지 및 부정행위 감지. - 자연어 처리와 감성 분석. - 컴퓨터 비전과 이미지 인식 (의료 영상 진단, 자율주행 차량 등).
D. 용어정리
- 레이블(label): 학습데이터의 정해진 특징 (분류결과가 정답이 될 데이터)
ex) 고양이 이미지와 강아지 이미지를 주고 분류하는 머신러닝을 만든다고 가정한다.
이 때 학습에 사용하는 데이터가 강아지인지, 고양이인지 알려주는 정답을 레이블이라 한다.
- 하이퍼파라미터(Hyperparmeter): 모델의 구조나 학습과정을 제어하는 각종 변수들을 의미한다.
- Training Dataset : The sample of data used to fit the model
- Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters. The evaluation becomes more biased as skill on the validation dataset is incorporated into the model configuration
- Test Dataset: The sample of data used to provide an unbiased evaluation of a final model fit on the training dataset.
→ 완전하게 모델이 훈련되었을 때, 딱 한 번만 사용한다.
E. 마무리
- 다양한 머시러닝 알고리즘
- 텐서플로우(TesnsorFlow), 파이토치(PyTorch) 같은 머신러닝 라이브러리 및 프레임워크
보호소에서는 몇 시에 입양이 가장 활발하게 일어나는지 알아보려 합니다.
0시부터 23시까지, 각 시간대별로 입양이 몇 건이나 발생했는지 조회하는 SQL문을 작성해주세요.
이때 결과는 시간대 순으로 정렬해야 합니다.
- 이 문제의 주 포인트는 0 ~23시까지의 칼럼을 새로 만들어야 한다는 점이다.
- 입양이 일어난 시간은 7~ 19시 사이이므로 그 외 시간을 나타내야 한다.
SELECT H.HOUR
,COUNT(O.ANIMAL_ID) AS COUNT
FROM (
SELECT ROW_NUMBER() OVER(ORDER BY ANIMAL_ID) - 1 AS HOUR
FROM ANIMAL_OUTS
LIMIT 24
) AS H
LEFT JOIN ANIMAL_OUTS AS O
ON H.HOUR = HOUR(O.DATETIME)
GROUP BY 1
- ROW_NUMBER 함수를 이용해 1부터 24까지 번호를 생성한 후, 0 ~ 23까지의 숫자를 출력하기 위해 -1 를 하였다.
- 시간을 기준으로 생성한 숫자와 ANIMAL_OUTS 테이블의 DATETIME을 JOIN 하였다.
- 이 방법을 통해 시간별 입양 건수를 출력할 수 있었다.
B. 마무리
- 해당 방법은 튜터님께서 가르쳐 주셨다.
- 분명 SQL 강의를 들을 때 WINDOW 함수에 대해 배웠던 것 같은데 활용하고자 생각지도 못했다.
- 이번 문제를 풀면서 WINDOW 함수까지 다시 한 번 공부할 수 있어 유익한 시간이었다.
with recursive 임시테이블명 as(
select 초기값
union all
select 초기값을 이용하여 값을 재귀적으로 수행
from 임시테이블명
where 정지조건
)
- recursive
On computing - relating to or involving a program or routine of which a part requires the application of the whole, so that its explicit interpretation requires in general many successiveexecutions.
: 재귀함수 - 함수에서 자기 자신을 다시 호출해 작업을 수행하는 방식
2. 문제에 적용하기
보호소에서는 몇 시에 입양이 가장 활발하게 일어나는지 알아보려 합니다.
0시부터 23시까지, 각 시간대별로 입양이 몇 건이나 발생했는지 조회하는 SQL문을 작성해주세요.
이때 결과는 시간대 순으로 정렬해야 합니다.
- 이 문제의 주 포인트는 0 ~23시까지의 칼럼을 새로 만들어야 한다는 점이다.
- 입양이 일어난 시간은 7~ 19시 사이이므로 그 외 시간을 나타내야 한다.
WITH RECURSIVE TIME AS(
SELECT 0 AS NUM
UNION ALL
SELECT NUM+1
FROM TIME
WHERE NUM < 23)
SELECT TIME.NUM AS TIME
,COUNT(O.ANIMAL_ID) AS COUNT
FROM ANIMAL_OUTS O
RIGHT JOIN TIME
ON
HOUR(O.DATETIME) = TIME.NUM
GROUP BY TIME.NUM
ORDER BY TIME.NUM
- 0부터 23까지 있는 TIME 테이블을 임시로 생성하였다.
- ANIMAL_OUTS 테이블과 시간을 기준으로 JOIN 하여 문제를 풀었다.
B. 마무리
- 프로그래머스의 다른 사람들의 풀이를 보고 따라 풀어보았다. 이 방법 외에 다른 방법을 찾아 풀고 싶다.
이 글은 긴 글쓰기를 두려워하는 이들을 위해 조언을 제공한다. 효과적인 스토리텔링을 통해 독자의 흥미를 유지하고, 글의 목적을 명확히 하여 독자를 설득하는 것이 중요하다. 긴 글쓰기를 연습하기 위해 문단을 적절히 구성하고, 이야기의 흐름을 말로 설명해보는 것이 좋다. 또한, 임팩트 있는 메시지를 전달할 수 있도록 글의 구조를 이해하는 것이 필요하다.
C. 주요 포인트
스토리텔링과 긴 글쓰기 모두 타인을 이해시키거나 설득하기 위한 공통된 목표를 가지고 있다. 이 과정에는 일정한 시퀀스가 존재한다. 특히 긴 글은 깊이 있는 메시지를 효과적으로 전달하는 데 유용하다.
긴 글을 잘 쓰기 위한 방법 1. 문단 나누기: 글을 작성할 때 문단을 명확히 나누어 각 주제를 구분하고, 독자가 내용을 쉽게 이해할 수 있도록 한다. 2. 구조적 접근: 글의 주요 메시지를 중심으로 구조를 잡아야한다. 핵심 메세지를 명확히 하고 그에 맞추어 내용을 전개하는 것이 중요하다. 3. 말로 정리하기: 글을 쓰기 전에 내용을 말로 정리해본다. 이 방법은 생각을 정리하고 글의 흐름을 자연스럽게 구성할 수 있다. 4. 임팩트 있는 구성: 독자에게 강한 인상을 남길 수 있는 글을 구성하는 것이 중요하다. 효과적인 메시지를 전달하기 위해 각 문장을 신중하게 선택하고 배치해야 한다.
분량이나 포맷보다는 글쓰기의 접근 방식이 중요하다. 전달하고 싶은 메시지를 명확히 하며 글의 구성과 짜임새를 고민하는 것에서부터 시작하고자 노력하여야 한다.
D. 용어 정리
시퀀스: 하나의 상황이 시작되어 끝나는 곳까지 독립된 구성단위
시퀀스는 각 학계에서 쓰이는 뜻이 다르다. 교육계에서는 '학습에서, 단원이 발달하여 가는 차례' , 영화계에서는 하나의 이야기가 시작되고 끝나는 독립적인 구성단위로, 극의 장소, 행동, 시간의 연속성을 가진 몇 개의 장면이 모여서 이루어짐' 을 말한다. 카드놀이에서는 숫자가 연속된 석 장 이상의 같은 종류 카드를 시퀀스라 부르기도 한다.
sequence 연속적인 사건들, 차례로 배열하다, 배열 순서를 밝히다 등의 단어 뜻으로 설명되며, 영화에서 연속성 있는 하나의 주제, 정경으로 연결되는 장면을 시퀀스라 정의하기도 하였다.