A. 금일 학습 내용
- ADsP 3과목 내용 정리
1. 데이터 마트
- 정의: 데이터 웨어하우스로부터 특정 사용자가 관심을 갖는 데이터들을 주제별, 부서별로 추출하여 모은 비교적 작은 규모의 데이터 웨어하우스
- 시간/공간적인 효율성 기대
2. 데이터 전처리
- 데이터 정제 과정: 결측값, 이상값 처리
- 분석 변수 처리과정: 변수선택, 파생변수 생성 등
- 요약 변수: 기본적인 통계 자료를 추출한 데이터 마트에서 가장 기본적 변수
- 파생변수: 특정 조건을 만족하거나 특정함수에 의해 값을 만들어 의미(목적)을 부여한 변수
3. 데이터 탐색
- 탐색적 데이터 분석(EDA): 대략적인 특성 파악
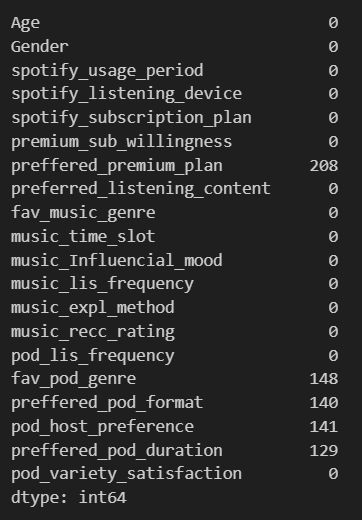
- 결측치(Missing Data)
대치방법
단순 대치법: 데이터 삭제, 결측값이 많은 대량의 데이터의 경우 데이터 손실 우려
평균 대치법: 데이터 평균으로 대치하여 완전한 자료 만듦
비조건부: 데이터 평균값 / 조건부: 실제값 분석 후 회귀분석 활용
단순확률대치법: K-Nearest Neighbor (K-근접군집)
다중대치법: 여러번의 대치를 통해 n개의 가상적 완전 자료 만듦
- 이상치(Outlier)
사용분야: 사기 탐지, 의료(예외 증세), 네트워크 침입탐지 등 부정사용 방지
판단방법
ESD(Extreme Studentized Deviation): 평균으로부터 3표준편차 만큼 떨어진 값 = 정규분포에서 전체 데이터의 0.3%를 이상치로 잡음
사분위수: 최솟값부터 최댓값까지 오름차순으로 정렬한 자료를 4등분했을 위치에 해당하는 값
IQR: Q1~Q3(사분범위)
중앙값: Q2
하한최솟값 Q1-(1.5*IQR) 보다 작음, 상한 최댓값 Q3+(1.5*IQR) 보다 큼 → 이상치
boxplot으로 식별 가능
4. 통계분석의 이해
- 모집단: 유한 집단 vs 무한 집단, 개념적으로 산정된 모집단을 지칭
- 통계자료 획득방법
전수조사
표본조사 → 대표성
표본: 조사하는 모집단의 일부분
모수(parameter): 모집단에 대해 알고자 하는 값, 모집단의 특성치
통계량: 모수를 추론하기 위해 구하는 표본의 값들로 숫자 하나로 특징을 나타냄 = 데이터를 요약한 수치
- 표본 추출 방법
단순 랜덤 추출법
계통 추출법: 계층
집락(군집) 추출법 (cluster sampling)
층화 추출법
비례층화 추출법: 전체 데이터 분포 반영 O
불비례 층화 추출법: 전체 데이터 분포 반영 X
- 측정과 척도
측정방법
질적척도: 명목 척도(출생지 등) VS 서열 척도(선호도, 순위)
양적척도: 구간 척도(온도 등) VS 비율 척도(0 값이 존재 & 모든 사칙 연산 O)
척도에 따라 데이터 분석 방법 상이
- 기술통계: 데이터 특징 뽑기
- 추리통계: 기술통계 + 확률 → 전체 OR 미래 추측
수집된 자료 이용하여 모집단에 대한 의사결정
모수 추정, 가설 검증, 예측
5. 기초 통계 용어
- 자료, (모)평균(기댓값), 중앙값, 최빈값
- 분산: 데이터의 흩어진 정도를 나타냄
데이터의 각 관찰값이 평균으로부터 얼마나 떨어져 있는지
데이터의 변동성 표현
분산값의 총 합 = 0
- 표준편차: 분산의 제곱근
데이터 포인트들이 평균으로부터 얼마나 떨어져 있는지 평균적 정도 측정
- 백분위수: 순서대로 정렬 시 특정 백분위 위치에 있는 데이터 값 → 범위 파악
- 첨도: 평균에 얼마나 많이 밀집되어 있나. 분포 형태 설명
- 왜도: 데이터 분포가 얼마나 비대칭인가
왜도 >0: 왼쪽으로 밀집
왜도 <0: 오른쪽으로 밀집
- 상관분석: 두 변수 간의 관계를 분석하기 위해 공분산, 상관관계 활용
- 공분산: 두 변수 간의 상관관계를 나타내는 통계적 척도 → 두 변수가 함께 어떻게 변하는가
- 선형관계: 두 변수가 함께 움직이는 방향과 그 크기에 대한 것
- 상관관계: 두 변수의 선형관계의 강도와 방향 → 두 변수 비교 위함
두 변수 간의 상관 정도를 -1 ~ 1 까지 숫자로 표현해서 측정
6. 확률
- 정의: 특정 사건이 일어날 가능성/ 표본공간(sample space) = 모든결과의 집합
- 조건부 확률: A가 발생한 가정 아래 B사건이 발생할 확률
- 독립사건: 두 사건이 서로 영향X
한 사건 발생 여부가 다른 사건에 아무런 정보 제공 X
- 배반사건: 두 사건이 동시에 발생할 수 X → A 발생 시 B 발생 불가
7. 확률 변수
- 정의: 표본 공간에 있는 모든 원소들을 수치적 값으로 만드는 함수
- 확률함수: 확률 변수에 의해 정의된 실수를 확률(0~1)에 대응시키는 함수
8. 확률 분포
- 정의: 확률함수 (확률 변수가 특정한 값을 가질 확률을 나타내는 함수)가 그리는 패턴
- 이산확률분포(확률질량함수): 확률변수를 셀 수 있음
- 연속확률분포(확률밀도함수): 확률변수를 셀 수 없음
9. 이산확률분포
- 베르누이 분포
확률변수가 0 또는 1, 두 개의 결과만 갖는 분포
- 이항분포
n번의 베르누이 시행(성공 or 실패)에서 k번 성공할 확률의 분포
0~n 사이의 값
- 다항분포
이항분포의 확장 개념
n번의 시행에서 각 시행이 3개 이상의 결과를 나타냄
- 포아송 분포
시간, 공간에서 발생하는 사건의 발생 횟수에 대한 확률 분포
발생횟수 = 확률 변수
- 기하분포
성공확률이 p인 베르누이 시행에서 첫 번째 성공이 있기까지 k번 실패할 확률
확률변수: 첫 성공이 일어나기 위해 필요한 시행 횟수
10. 연속확률분포
- 균일 분포
가능한 값이 실수의 어느 특정 구간 전체에 해당하는 확률 변수
어떤 특정 구간이 주어져도 동일한 확률
- 정규분포
일반적인 데이터 분포 중 해당 분포가 대부분의 자연현상과 비슷함
종모양, 좌우대칭, 중간값 = 평균값
표준편차의 경우 작을 수록 퍼져보이는 (납작한) 그래프 나타냄
- t-분포
통계적으로 표본으로부터 모집단의 평균에 대한 추정을 할 때 사용
sample이 적을 때 표준정규분포보다 눌린 그래프
sample이 많을 수록 표준정규분포에 가까워짐
-2~ 2 사이의 값을 일반적인 상황으로 봄
평균 = 0
- 카이제곱 분포
표준정규분포를 따르는 확률변수들의 제곱을 합한 분포
표준정규분포의 분산의 분포 → 몇 개의 표준정규분포를 더했는가 (자유도 몇개 더함?)
0 이상의 값, 양수
이상적인 값 =1
- f-분포
카이제곱의 비율을 따름
기준 =1
1보다 큰 값은 유의미하다 봄
카이제곱이 2개가 사용됨
분모 → 집단 내 분산 , 분자 → 집단 간 분산
f value =1 → 굉장히 규칙적으로 분포
f value >1 → 집단 간 유의미한 차이가 있음
자유도가 커질 수록 정규분포에 가까워짐
11. 추정
- 모수: 모집단에 대해 알고자 하는 값
- 점추정: 표본의 통계량을 이용해 모수를 하나의 값으로 추정
- 구간추정: 표본의 통계량을 이용해 모수를 하나의 값이 아닌 구간으로 추정
12. 가설검정
- 귀무가설: 기존에 알려진 사실/ 아무런 차이가 없다
- 대립가설: 주장/ 차이가 있다
- 오류 종류
1종 오류: 실제로는 귀무가설이 참인데 이를 기각하는 오류
2종 오류: 실제로는 귀무가설이 거짓인데 이를 채택하는 오류
13. 기술통계
- 자료 정리 및 요약 방법
- 표, 그림, 통계량 등을 사용하여 자료의 특성을 파악
14. 추리통계
- 전체 자료를 부분으로 추측
- 수집된 자료를 통해 모집단을 추측
15. 변수
- 종속변수: 연구자가 관심 있는 변수
- 독립변수: 종속변수에 영향을 미치는 변수
16. 산점도
- 변수의 값들을 x, y축 상의 점으로 표시한 그래프
- 두 변수의 관계를 시각적으로 표현
- 선형관계, 함수관계, 이상값, 집단 구분
17. t-검정
- 두 집단의 평균 차이를 비교
- t-value, 신뢰구간, p-value 활용
18. 분산 분석(ANOVA)
- 세 개 이상의 그룹 간의 평균 차이 검정
- f-value, 사후 분석, 분석 가정
19. 교차분석
- 범주형 변수 간의 관계 분석
- 적합도 검정, 독립성 검정, 동질성 검정
20. 상관분석
- 두 변수 간의 관계의 정도를 측정
- 상관계수, 피어슨 분석, 스피어민 분석
21. 회귀분석
- 독립변수와 종속변수 간의 관계 모델링
- 단순회귀, 다중회귀, 다항회귀, 비선형회귀, 로지스틱회귀
22. 정규화 선형회귀
- 과적합 방지를 위해 사용
- L1 규제(라쏘), L2규제(릿지), 엘라스틱넷
23. 일반화 선형회귀
- 범주형 자료 분석
- 로지스틱 회귀분석
24. 다차원 척도법(MDS)
- 객체 간의 근접성을 시각화하여 표현
- 유사성/비유사성 표현
25. 주성분 분석
- 차원 축소 기법
- 상관성이 높은 변수들의 선형 결합으로 주성분 추출
- 다중공산성 문제 해결
26. 시각화
- 스크리 플롯: 주 성분 수 결정
27. 시계열 분석
- 시간의 흐름에 따른 자료 분석
- 미래 예측 가능
28. 자기상관성
- 시계열 데이터에서 시간 간의 데이터 상관성 분석
- 시계열 데이터의 특징을 파악
'Today I Learned' 카테고리의 다른 글
| [내일배움캠프_데이터분석] 7주차 수요일 TIL _ window function (0) | 2024.08.07 |
|---|---|
| [내일배움캠프_데이터분석] 7주차 화요일 TIL _ CTE (0) | 2024.08.06 |
| [내일배움캠프_데이터분석] 6주차 금요일 TIL _ 기초통계학 (0) | 2024.08.02 |
| [내일배움캠프_데이터분석] 6주차 목요일 TIL _ 구조 생각하기 (0) | 2024.08.01 |
| [내일배움캠프_데이터분석] 6주차 수요일 TIL (0) | 2024.07.31 |