A. 금일 학습 내용
파이썬을 활용한 머신러닝 이해 및 라이브러리 활용
1. 필요한 라이브러리 설치
!pip install scikit-learn
!pip install numpy
!pip install pandas
!pip install matplotlib
!pip install seaborn
2. 라이브러리 불러오기
import sklearn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
3. 데이터 생성하기
# 키 몸무게 데이터
weights = [87, 81, 82, 92, 90, 61, 86, 66, 69, 69]
heights = [187, 174, 179, 192, 188, 160, 179, 168, 168, 174]
print(len(weights)) #10
print(len(heights)) #10
4. Dictionary 형태로 데이터 생성
body_df = pd.DataFrame({'height':heights, 'weight':weights})
body_df.head(3)
5. 키와 몸무게 간의 산점도로 관계 살펴보기
sns.scatterplot(data=body_df, x='weight',y='height')
plt.title('Weight vs Height')
plt.xlabel('Weight(kg)')
plt.ylabel('Height(cm)')
plt.show()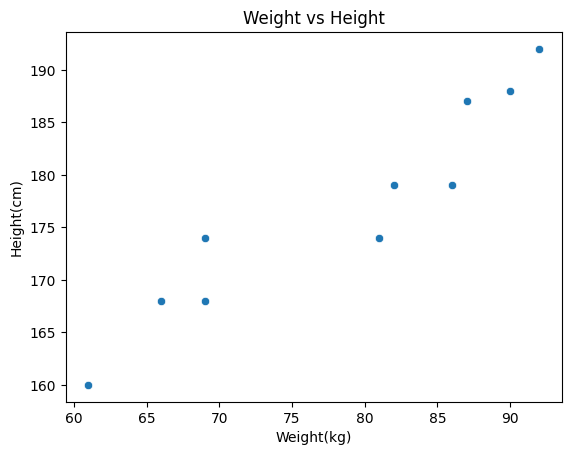
6. 훈련을 위한 선형회귀 모델 구축
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
type(model_lr)
7. x변수 및 y변수 지정
X = body_df[['weight']]
Y = body_df[['height']] # y는 관습적으로 소문자- DataFrame[ ] : Series (데이터 프레임의 컬럼)
대괄호([ ]) 는 데이터프레임 Series를 의미한다.
- DataFrame[[ ]] : DataFrame
이중 대괄호([[ ]])는 데이터프레임을 의미하며 결과를 2차원으로 나타내야 함으로 이중 대괄호를 사용한다.
이는 추후 훈련 시 데이터 차원 문제 발생을 방지한다.
8. 데이터 훈련
model_lr.fit(X=X, y=Y)- X는 대문자로 y 는 소문자로 쓰는 것이 관습적인 방법이라 한다.
9. 가중치 및 편향 구하기
# 가중치(w1)
print(model_lr.coef_)
# 편향(bias, w0)
print(model_lr.intercept_)- 가중치는 'coef_' 를 사용하며 '_' 작성을 잊지 말아야 한다. 미작성 시 오류가 발생할 수 있다.
- 편향은 'intercept_'를 사용하며 가중치와 동일하게 '_' 을 작성하여야 한다.

해당 값은 w1과 w0에 넣어준다.
w1 = model_lr.coef_[0][0]
w0 = model_lr.intercept_[0]
10. 단순선형회귀식 확인하기
print('y = {}x + {}'.format(w1.round(2),w0.round(2)))
- y(height)는 x(weight)에 0.86을 더한 뒤 109.37를 더하면 된다.
- 가중치: 0.86, 편향 109.37 값을 갖는다.
11. 예측값 구하기
body_df['pred'] = body_df['weight']* w1 + w0
body_df.head(3)
- 예측값을 구하여 'pred' 열에 새로 저장한다.
12. 오차값(에러값) 구하기
body_df['error'] = body_df['height']-body_df['pred']
body_df.head(3)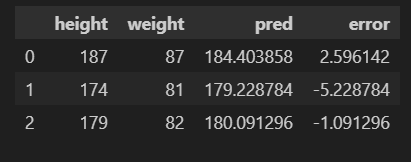
- '실제값 - 예측값' 은 오차값을 의미한다.
- 오차값의 총합은 0 이므로 error 값에 제곱을 하여 더하여 유의미한 값을 갖게 한다.
body_df['error^2'] = body_df['error']*body_df['error']
body_df.head(3)
13. 모델 평가하기
1) MSE(Mean Squared Error, 평균제곱오차) 수동 계산
body_df['error^2'].sum()/len(body_df)- MSE : 10.152939045376309
2) MSE 자동 계산
from sklearn.metrics import mean_squared_error
y_true = body_df['height'] # 실제값
y_pred = body_df['pred'] # 예측값
mean_squared_error(y_true, y_pred)- MSE를 구하는 내장함수는 mean_squared_error 함수이다.
- MSE : 10.152939045376309
3) R Square(결정계수) 값을 활용한 평가
from sklearn.metrics import r2_score
r2_score(y_true,y_pred)
y_pred2 = model_lr.predict(body_df[['weight']])
mean_squared_error(y_true,y_pred2)- R Square(결정계수) 값은 평균대비 설명력을 의미한다.
- 값이 0이면 설명력 없음으로 해석되고, 1이 가장 높은 설명력을 갖는다고 할 수 있다.
- r2_score 내장함수는 결정계수를 구하는 함수로, 선형 회귀 분석 시 사용되는 회귀 모델의 적합도를 나타내는 지표 중 하나이다.
- predict 함수는 학습한 데이터를 바탕으로 새로운 데이터가 입력되면 그에 맞는 결과를 예측한다.
- mean_squared_error를 활용해 평가하면 아래의 값이 산출된다.
MSE : 10.152939045376309
4) 시각화
- 3가지 방법으로 나온 MSE의 값이 모두 동일하다
- 이를 산점도 그래프에 선형식을 그리면 아래와 같은 그래프가 완성된다.
sns.scatterplot(data=body_df, x='weight',y='height')
sns.lineplot(data=body_df,x='weight', y='pred',color = 'red')
- 선형회귀식과 데이터, 그리고 그 데이터의 오차가 위 그래프에 모두 담겨 있다.
B. 마무리
- 더 복잡한 모델을 학습한다.
- 큰 틀을 잡아가는 것을 첫 번째 목표로 공부하자.
'Today I Learned' 카테고리의 다른 글
| [TIL] 로지스틱 회귀분석(분류분석) (0) | 2024.08.16 |
|---|---|
| [TIL] map( ), 문자열 나누기 (0) | 2024.08.14 |
| [TIL] 알고리즘 코드카타_행렬 (0) | 2024.08.12 |
| [내일배움캠프_데이터분석] 7주차 금요일 TIL _ SQL 문제해결 (0) | 2024.08.09 |
| [내일배움캠프_데이터분석] 7주차 수요일 TIL _ window function (0) | 2024.08.07 |