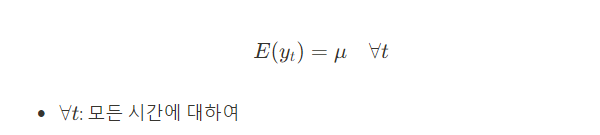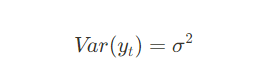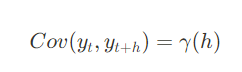데이터 분석에 대해 배우면서 가장 많이 접하게 되는 학문은 '통계학'이다. 교육과정에 확률과 통계가 있지만, 이해보다는 암기 위주로 공부했던 기억이 난다. 데이터 분석가 혹은 데이터 사이언티스트가 되고자 할 때, 통계에 대해 제대로 아는 것이 중요하다 판단된다. 이 기회에 확률과 통계에 대해 속속들이 파헤쳐보고자 한다.
지금부터 쓰일 글은 https://recipesds.tistory.com/(친절한 데이터 사이언티스트 되기 강좌, 히언님의 tistory)과, 황세웅 저자의 '데이터 분석가가 반드시 알아야 할 모든 것' 이란 책이 그 배경지식이 될 것이다.
B. 확률과 통계가 무엇인가?
1. 사전적 의미
1) 확률: 일정한 조건 아래에서 어떤 사건이나 사상(事象)이 일어날 가능성의 정도, 또는 그런 수치 (출처: 네이버 사전).
수학적으로는 1을 넘을 수 없고, 음이 될 수도 없다. 확률 1은 항상 일어남을 의미하고, 확률 0은 절대로 일어나지 않음을 의미한다.
2) 통계: 집단적인 현상이나 수집된 자료의 내용에 관한 수량적인 기술.
대상이 되는 집단을 일정한 시점에서 파악하는 것을 정태 통계, 일정한 기간에서 파악하는 것을 동태 통계라 하며, 사회나 자연현상을 정리·분석하는 수단으로 쓰기도 한다.
3) 확률분포: 확률변수의 분포 상태.
어떤 시행에서 일어날 수 있는 사건마다 그 확률값을 대응하게 한 것이다.
4) 확률변수: 한 시행에서 표본 공간을 정의역으로 하는 실수 함수.
확률 공간의 점인 근원 사건에 수를 대응하게 하는 함수.
* 정의역: 두 변수 x, y 사이에 y가 x의 함수로 나타내어질 때에 x가 취할 수 있는 값의 범위
* 하나의 시행에서 n개의 사건 가운데 하나가 일어나며 두 개가 동시에 일어나는 일은 없을 때, 그 각각의 사건을 이르는 말
2. 통계와 확률 간의 관계
1) 통계는 표본을 통해서 모집단을 추론하고 확률을 이용해서 계산하고, 결과를 표현한다.
2) 모집단의 특성을 설명하는 수를 모수(parameter)라 부르며, 모평균, 모분산, 모표준편차, 모비율, 모상관관계등을 의미한다.
친절한 데이터 사이언티스트 되기 강좌_확률과 통계의 관계
3. 그래서 결론은?
1) 표본을 통해서 평균과 분산을 추론할 수 있다면 모집단도 어느정도 확률 분포로 설명할 수 있다.
2) 표본 평균을 통해 모집단의 평균을 추정할 때 표본 평균은 모집단의 분포와 상관없이 Gaussian을 이룬다.
3) 그렇기 떄문에 확률로 모수를 표현할 수 있다.
4) 모수를 추론하기 위해 표본을 뽑게 되는데, 이 표본에서 나오는 여러 수치들을 통계량(=확률변수) 이라 한다.
5) 모집단의 정체를 알 수 없을 때 표본을 가지고 모집단을 확률로 예측하는 것이다.
친절한 데이터 사이언티스트 되기 강좌_ 모집단과 표본
C. 기술통계와 추론통계
1. 기술통계 (descriptive statistics)
1) 정의 : 문자 그대로 주어진 데이터의 특성을 사실에 근거하여 설명하고 묘사하는 것 = 전체 데이터를 쉽고 직관적으로 파악할 수 있도록 설명해주는 것
2) 기법 : 평균(가중평균, 기하평균, 조화평균 등), 중앙값, 최빈값 등
3) EDA : 데이터 요소들을 수치적으로 설명할 필요가 있을 때 사용되는 방법으로, 해당 과정을 통해 날것의 데이터를 의사결정을 위한 정보로 탈바꿈하는 것이다.
4) 시각화 : 단순한 수치 보다는 그림이나 그래프를 통해 표현하는 것이 훨씬 효율적으로 시각화하여 많이 사용한다.
2. 추론 통계 (inferential statistics)
1) 정의 : 표본 집단으로부터 모집단의 특성을 추론하는 것
2) 예시 : A학급의 평균 키가 170cm 라고 했을 때, '학교 전체 학생의 평균 키가 167~173cm 구간 내에 존재할 확률이 어느 정도다.' 라는 식의 추론이 가능하다. 신뢰 구간을 구하는 것이 추론통계라 할 수 있다.
3) 방법 : 머신러닝 모델을 만들고 예측이나 분류를 하는 것
4) 필요 개념: 편향, 분산, 확률분포, 가설 검정, 유의도(p-value)
3. 기술 통계와 추론 통계의 통합적인 프로세스
통합적 프로세스
황세웅 저자가 기술 통계와 추론 통계에 대해 작성한 문장으로 마무리하고자 한다. 통계에 대해 처음 공부를 시작할 때 어떤 개념을 주로 공부해야하는지, 한 쪽 분야만 공부해도 되는 것인지 고민을 했던 내게 그 답을 해준 문장이다.
추론 통계가 기술 통계보다 더 중요하다고 단정 지을 수 없다. 기술 통계가 있어야 추론 통계가 가능한 것이고 기술 통계를 확실히 했을 때보다 정확한 인사이트를 얻을 수 있다. 첫 단추를 잘못 끼우면 결국 마무리도 제대로 딜 수 없다. 물론 추론 통계가 데이터 과학의 주축을 맡고 있지만 기술 통계는 그 기반과 같은 요소다.
보고서: 사용자가 분석하고자 하는 앱 혹은 웹사이트와 상호 작용하는 방식에 대한 일반적인 질문의 답을 찾을 수 있는지 미리 준비된 보고서로 확인할 수 있다.
탐색 분석: 표준 보고서 외에 고객 참여에 대한 보다 심층적인 통계를 제공하는 고급 분석 기법을 사용할 수 있다.
광고: 온라인 광고 활동을 분석, 이해, 개선할 수 있는 정보를 제공한다.
관리: 계정, 속성, 이벤트, 사용자 설정을 관리한다.
페이지 상단의 속성 선택기: 계정 또는 속성이 두 개 이상인 경우 모든 페이지에서 계정 또는 속성 간에 전환할 수 있다.
B. 이벤트 관리
이벤트는 페이지 조회수, 버튼 클릭수, 사용자 액션처럼 웹사이트 또는 앱에서 발생하는 활동에 대한 통계 정보를 제공한다. 대부분의 일반적인 이벤트는 Google Analytics에 웹사이트나 앱을 연결하면 자동으로 수집된다.
데이터 스트림 설정에서 향상된 측정을 사용 설정한 경우, 코드를 추가하지 않아도 속성에서 더 많은 이벤트를 자동으로 수집한다.
1) 자동수집 이벤트
자동수집 이벤트는 앱 또는 사이트와의 기본적인 상호작용에 의한 트리거로 발생한다. 별도로 명시되지 않는 한 애널리틱스는 Android 및 iOS앱의 이벤트를 수집한다. 이러한 이벤트의 이름과 매개변수는 원시 이벤트 데이터에 엑세스할 때 유용하다. 다음 링크를 통해 각 이벤트 매개변수와 Google 애널리틱스에서 각 매개변수가 측정기준 또는 측정 항목을 업데이트하는 방식을 알아볼 수 있다. https://support.google.com/analytics/answer/9234069
Google Analytics에서 자동으로 수집하는 이벤트 외에 나의 비즈니스와 관련된 다른 이벤트도 수집할 수 있다. 추천이벤트란 Google Analytics는 업종에 따라 비즈니스에 유용할 수 있는 일반적인 이벤트를 추천한다. 맞춤 이벤트의 경우, 처음부터 만들 수도 있다. 추천 이벤트와 맞춤 이벤트는 모두 웹사이트 태그 또는 앱에 대한 추가적인 구현단계가 필요하다는 공통점이 있지만 아래와 같은 차이점이 있다.
구분
추천이벤트
맞춤이벤트
차이점
사용자가 구현하지만, Google Analytics에서 이미 인식한 이름과 매개변수가 사전에 정의되어 있다. 다음의 이벤트를 웹사이트나 모바일 앱에 추가하여 추가활동을 측정하고 더 유용한 보고서를 생성할 수 있다.
내가 정의하는 이름과 일련의 매개변수로 구성되는 이벤트이다. 맞춤 이벤트를 사용하면 애널리틱스에서 자동으로 수집하거나 추천하지 않는 특정 비즈니스 데이터를 수집할 수 있다.
3) 측정기준 및 측정항목
Google Analytics는 측정기준과 측정항목을 사용하여 이벤트, 이벤트 매개변수, 사용자 속성에서 모든 데이터를 수집하고 보고서로 컴파일(compile, 소스코드를 바이너리 코드로 변환하는 과정)한다. 측정기준은 '누가 무엇을 어디에서?' 란 질문에 답하지만 측정항목은 '얼마나 많이?' 란 질문에 답한다. 자동 수집되는 이벤트 및 매개변수는 보고서에 이미 생성되어 사용할 수 있는 관련 측정기준 및 측정항목이 있다.
웹사이트나 앱에서 새 이벤트 및 맞춤 이벤트와 관련 매개변수를 구현하면 이러한 새로운 데이터를 Analytics로 전송한다. 이 경우 보고서에서 확인하고자 한다면, 데이터에 해당하는 측정기준과 측정항목을 만들어 사용하면 된다. 이는 사용자가 직접 만들었다는 점을 제외하면 기본 측정기준 및 측정항목과 동일하다. 자체적인 맞춤 측정 기준과 측정항목을 만들 때는 범위를 정확하게 알고있어야 한다.
★ 이벤트 범위 측정 기준: 사용자가 수행하는 액션에 대한 정보를 제공한다. 예를 들어, 누군가 웹사이트에서 게시글을 조회한 경우 게시글 제목이 이벤트 범위측정 기준일 수 있다.
☆ 사용자 범위 측정 기준: 액션을 수행한 사용자에 대한 정보를 제공한다. 예를 들어, 게시글을 본 사용자의 기기가 사용자 범위 측정기준일 수 있다.
★ 상품 범위 측정 기준: 사용자가 상호작용한 제품 또는 서비스에 대한 정보를 제공한다. 예를 들어, 누군가가 장바구니에 물병을 추가한 경우 물병의 색상이 상품 범위 측정기준일 수 있다.
자동으로 수집되는 측정기준과 측정항목에는 이미 범위가 지정되어 있다. 맞춤 측정기준을 새로운 이벤트와 매개변수로 생성할 경우에는 범위를 선택하여야 한다. 맞춤 측정항목은 이벤트 범위만 가능하다.
C. 수집한 데이터 관리 및 필터링
1) 교차 도메인 측정
보고가 중단되지 않도록 하기 위해 교차 도메인 측정을 구현한다. 두 웹사이트 모두의 사용자 여정에 대해 보고 가능하다.
2) 원치 않는 추천
웹사이트 트래픽의 소스를 분석하여 고객이 어디에서 본인의 웹사이트로 이동했는지에 대한 정보를 소스, 즉 추천이라 한다. 원치 않는 추천이란 웹사이트 및 고객 거래를 관리하는데 사용하는 서드 파티 도구처럼 데이터에 포함시키고 싶지 않은 소스를 거쳐 웹사이트에 도달한 트래픽 세그먼트를 말한다. 데이터 스트림, 태그 설정 구성, 원치 않는 추천나열 등의 메뉴를 활용하여 관리 규칙을 만들 수 있다.
3) 데이터 필터
웹사이트에서 보고 싶은 데이터만 확인하고 싶을 때 데이터 필터를 사용할 수 있다. 데이터 필터를 사용하면 수신되는 이벤트 데이터를 Google Analytics에서 처리하지 않도록 제외할 수 있다. 이 설정은 이전 데이터에는 영향을 않지만, 필터를 만든 이 후의 이벤트 데이터는 영구적으로 표시되지 않는다. 추후 복구 또한 불가능하다. 필터를 삭제한면 그 이후 데이터는 처리되지만, 이미 제외된 데이터는 복구할 수 없다. 그렇기에 신중히 데이터 필터를 사용하여야 한다. 필터는 아래의 두 옵션 중 선택한다.
★ 개발자 트래픽: 디버그 모드를 사용하는 개발자의 활동을 제외한다.
☆ 내부 트래픽: 특정 IP 주소 또는 IP 주소 범위에 해당하는 사용자를 제외한다.
D. Google Analytics 전환 관리
전환이란 나의 비즈니스에 중요한 영향을 주는 사용자 액션을 말한다. 사용자가 내 매장에서 구매하거나 구독하는 경우를 예로 들 수 있다. 전환을 측정하려면 먼저 관련 사용자 상호 작용을 이벤트를 수집 중인지 확인하여야 한다. 이는 기존 이벤트 또는 자동 수집 이벤트이거나 맞춤 이벤트일 수 있다.
이벤트가 아직 발생하지 않은 경우 이벤트가 표에 곧바로 표시되지 않을 수 있다. 이러한 경우 '관리자' 탭으로 이동한 후 '전환'으로 이동하여, 새 전환 이벤트를 선택하고 전환으로 표시할 이벤트 이름을 입력하면 나타난다.
비즈니스에서 가장 중요한 이벤트의 하위 집합이라 볼 수 있다.
E. 보고서
보고서에서 주요 비즈니스 측정항목을 빠르게 확인한 후 더 알고 싶은 부분을 깊이 있게 탐구할 수 있다. Google Analytics 속성을 처음 설정할 때 비즈니스 목표를 선택하라는 메시지가 표시된다. 선택한 목표애 따라 특정 보고서가 생성된다.
보고서는 크게 2 종류로 나누어 볼 수 있다.
★개요보고서: 각기 다른 목표에 초점을 맞춘 여러 카드로 주제 관련 정보를 요약한다.
☆ 세부정보 보고서: 한 두가지 측정기준을 통해 데이터를 더욱 상세하게 살펴볼 수 있다.
개요 보고서를 구성하는 카드는 특정 목표에 초점을 맞춘다. 다음의 도구는 데이터를 조정할 수 있는 설정 중 일부이다. 측정기준 또는 측정항목 선택 도구는 카드에 표시되는 데이터를 변경할 수 있다. 이 경우 사용자 매체가 측정기준이 된다. 기간 선택기는 보고 기간을 선택할 수 있다. '사용자 획득 보기'는 관련 보고서와 연결되어 있다. 카드 주제와 관련하여 더욱 상세한 보고서 열람이 가능하다.
사용자 변동 추이는 선그래프로 나타나며 선택 기간 동안 웹사이트를 방문한 총 사용자 수를 일별로 볼 수 있다. 해당 도구를 사용하여 트래픽 증가로 구독의 증감여부를 확인할 수 있다. 사용자 매체별 신규 사용자는 막대그래프로 나타낼 수 있다. 이 차트는 자연유입, 추천, 이메일 등 사용자의 유입 경로를 알 수 있도록 매체별로 분류되어 있다. 신규 사용자를 다수 유입시켜 구독을 증가시킬 가능성이 있는 특정 매체가 있는지 확인할 수 있다.
탐색 메뉴의 '보고서'는 다양한 데이터 포인트와 유용한 정보를 대략적으로 보여주는 카드가 포함된 보고서 개요가 표시된다. 실시간 보고서를 활용하면 최근 30분 이내에 발생한 이벤트를 표시하여 이용자의 활동을 실시간으로 모니터링할 수 있다. 사용자가 현재 어떤 방식으로 나의 비즈니스와 상호작용하고 있는지에 관하여 알아보기 쉽도록 카드 기반의 레이아웃을 사용한다. 해당 보고서에서는 '1일 프로모션을 통해 사이트 또는 앱으로 트래픽이 유입되고 있는지를 확인', '블로그, 사회연결망 게시물 또는 트윗의 트래픽이 미치는 즉각적인 영향 모니터링', '추적 코드가 사이트 또는 앱에서 작동하고 있는지 확인' 할 수 있는 작업을 진행할 수 있다.
그 이외 기본 보고서는 모두 동일한 기본 형식을 따른다. 개요 보고서가 맨 위에 표시되고 이어 세부정보 보고서가 표시된다.
★ 획득: 고객이 어떤 경로로 유입되는가
☆참여도: 고객이 참여하는 콘텐츠는 무엇인가
★ 수익창출: 고객의 활동에는 어떤 것이 있나 ☆유지: 고객이 재방문하는가
★ 사용자 속성: 고객은 어떤 특성을 가지고 있는가
☆기술: 고객이 웹사이트나 앱에 엑세스하는 데 사용하는 것이 무엇인가
보고서 필터를 사용하면 보고서에 표시할 데이터를 관리할 수 있다. 필터를 사용하면 데이터를 이해하고, 전체 추이를 파악하고, 중요한 정보를 세부적으로 살피는데 도움이 된다. 또한 비교 규칙을 작성하여 데이터를 나란히 비교할 수 있다. 기본값 및 맞춤 측정기준을 적용한 비교를 추가할 수 있다. 하나의 비교에서 여러 개의 측정기준을 조합하는 것도 가능하다.
가장 중요한 것은 보고서는 측정기준 및 측정항목으로 구성된다는 사실이다.
보고서는 측정기준 및 측정항목으로 구성된다. 측정기준 값을 사용해 데이터를 필터링하고 맞춤설정하여 특정 통계를 얻을 수 있다.
GA 사용 전 관련 이론적 배경에 대해 알아보았다. 다음에는 직접 실습하며 그 툴을 다뤄볼 예정이다.
데이터 모델링이란 정보 시스템 구축을 위해 데이터 관점의 업무를 분석하는 과정, 현실세계의 데이터를 약속된 표기법에 의해 표현하는 과정, 데이터 베이스를 구축하기 위한 분석 및 설계의 과정을 아루는 말이다. 데이터 모델링의 목적은 크게 두가지로 정리할 수 있다.
① 업무에 필요한 정보를 정확하게 정의하고 표현하여 업무를 분석한다.
② 분석 모델을 통해 실제 데이터 베이스를 생성하여 데이터를 관리한다.
데이터 모델링은 3단계로 이루어진다.
현실세계를 조직이나 사용자가 필요로 하는 데이터의 요구사항을 찾고 분석하는 과정의 개념적 모델링(Conceptual Data Modeling),
정보의 논리적인 구조와 규칙을 명확하게 표현하는 기법/과정의 논리적 모델링(Logical Data Modeling),
모델을 어떻게 하드웨어에 표현할 것인지 다루는 과정의 물리적 모델링(Physical Data Modeling)
으로 나뉜다.
개념적 데이터 모델링은 추상화 수준이 가장 높고 업무 중심적인 모델링이다. 전사적 관점에서 기업의 데이터 모델링이다.
논리적 데이터 모델링은 비즈니스 데이터에 존재하는 사실을 인식하여 기록하는 모델링이다. 정규화를 수행하여 데이터 모델의 독립성 확보하는 단계이다.
물리적 모델링은 구축할 데이터베이스 관리 시스템에 테이블, 인덱스 등을 생성하는 단계로, 성능, 보안, 가용성을 고려하여 구축한다.
B. 3층 스키마(3 -Level Schema)
사용자, 설계자, 개발자가 데이터베이스를 보는 관점에 따라 데이터베이스를 기술하고 이들 간의 관계를 정의한 표준 View(뷰) : 3단계 계층으로 분리하여 독립성을 확보한 각 계층 Schema(스키마): 계획이나 도식을 가리키는 영어 낱말로, 자료를 저장하는 구조와 표현법을 정의하는 것을 뜻함
외부 스키마란 여러 개의 사용자 관점으로 구성된다. 즉, 개별 사용자(= 사용자 관점)가 보는 DB 스키마이다.
개념 스키마란 데이터 베이스의 물리적인 저장 구조에 대한 부분은 숨기고 데이터의 전체적인 구조와 관계에 대해 집중한다. 모든 응용시스템이나 사용자(=설계자 관점, 통합 관점)가 필요로 하는 데이터를 통합한 조직 전체의 DB를 기술한다.
내부 스키마란 DB가 물리적으로 저장된 형식을 말한다. 물리적 장치에서 데이터가 실제적으로 저장되는 완전히 구체적인 방법을 표현하는 스키마이다. 개발자 관점에서 바라보는 스키마이며, 물리적 저장 구조와 관련이 깊다.
간단히 정리하자면, 3층 스키마란 데이터베이스를 3가지의 큰 범주로 분리하자는 개념이다. 사상(Mapping)은 각 범주간의 요청/응답을 전송하는 것이다. 외부 스키마에서 요청이 들어오면 DBMS에 의해 개념 스키마-내부 스키마로 전달되는데 여기에서 요청과 응답을 변환하는 프로세스를 사상(Mapping)이라 한다.
개념 스키마는 전체 데이터 베이스의 설계를 설명할 수 있는 모델로 데이터 구조의 구현 정보와 같은 내부 상세 정보는 보지 못하지만 구조, 관계 등은 볼 수 있다.
내부 스키마는 물리적 저장 구조를 갖춘 모델을 의미한다.
데이터 독립성이란 상위 스키마를 변경하지 않고 하나의 계층에서 스키마를 변경할 수 있는 능력을 의미한다. 데이터 베이스의 여러 레벨에서 구조를 수정할 때, 하위 레벨 스키마를 변경하더라도 상위 레벨 스키마를 건드릴 필요가 없는, 영향을 미치지 않는 것을 의미한다.
논리적 독립성은 사용자 특성에 맞게 변경이 가능하며, 개념 스키마가 변경되어도 외부 스키마에는 영향을 미치지 않도록 지원한다. 논리적 구조가 변경되어도 응용프로그램에 영향이 없다.
물리적 독립성은 물리적 구조의 영향 없이 개념 변경이 가능하다. 내부 스키마가 변경되어도 개념 스키마는 영향을 받지 않도록 지원하며, 저장장치의 구조 변경은 응용프로그램과 개념 스키마에 영향을 주지 않는다.
정리하자면, 데이터가 저장되는 파일의 구조를 바꿨다고 해서(내부 스키마). 전체적인 데이터 베이스 구조/설계가 달라지거나(개념 스키마) 응용 프로그램단(외부 스키마)이 변경되면 안된다. 또한, 데이터베이스를 바라볼 수 있는 관점을 3가지로 나눌 수 있는데, 그 각각은 논리적/물리적으로 독립적이면 좋다.
C. 식별자
하나의 엔터티에 구성되어 있는 여러 개의 속성 중에서 엔터티를 대표할 수 있는 속성 하나의 엔터티는 반드시 하나의 유일한 식별자가 존재해야함
식별자는 자신의 엔터티 내에서 대표성을 갖는지, 스스로 생성되었는지에 따라 혹은 속성의 개수를 기준으로 분류할 수 있다. 주식별자는 엔터티 내에서 각 인스턴스를 구분할 수 있는 구분자이며 다른 엔터티와 참조 관계를 연결할 수 있다. 보조 식별자는 엔터티 내에서 각 인스턴스를 구분할 수 있는 구분자 이거나 대표성을 갖지 못해 참조 관계 연결을 하지 못한다. 스스로 엔터티 내에서 정의되는 식별자를 내부 식별자, 다른 엔터티와의 관계를 통해 다른 엔터티로부터 받아오는 식별자를 외부 식별자라 한다. 속성의 수로 분류되는 식별자는 단일 식별자와 복합 식별자라 한다. 마지막으로, 본질 식별자는 업무에 의해 만들어지는 식별자를 뜻하고, 인조 식별자는 업무적으로 만들어지지는 않지만 원조 식별자가 복잡한 구성을 갖고 있기 때문에 인위적으로 만든 식별자이다.
ERD를 통해 살펴보면 아래 그림과 같다. 하나의 엔터티에서 여러 식별자로 구분될 수 있음을 알 수 있다.
자식 엔터티의 주식별자로 부모 주식별자가 상속되는 경우를 식별자 관계(Identifying Relationship)이라 한다. 각 엔터티에 주식별자가 지정되고, 엔터티간 관계를 연결하면 부모와 자식 간의 관계가 생성된다.
분류
식별자 관계
비식별자 관계
목적
강한 연결관계의 표현
약한 연결관계의 표현
자식 주식별자 영향
자식 엔터티의 주식별자의 구성에 포함
자식 엔터티의 일반 속성에 포함
표기법
실선(IE), 버티컬바(Barker)
점선(IE)
연결 시 고려사항
1. 반드시 부모 엔터티에 종속되어야 함 2. 자식 주식별자 구성에 부모 엔터티의 주식별자 속성이 필요한 경우에 사용함 3. 상속 받은 주식별자 속성을 타 엔터티에 이전할 필요가 있음
1. 약한 종속 관계를 가짐 2. 자식 주식별자 구성을 독립적으로 구성할 경우에 사용함 3. 자식 주식별자 구성에 부모 주식별자 부분이 필요함 4. 상속 받은 주식별자 속성을 다른 엔터티에 차단할 필요가 있음 5. 부모 쪽의 관계 참여가 선택 관계임
주의: 자식 엔터티의 주식별자로 부모 주식별자가 상속되는 경우 식별자 관계는 비식별자 관계이다.
부모 엔터티 = 사원, 자식 엔터티 = 교육이력 → 사원의 사번을 가지고 교육이력을 만들어야 하기 때문이다.
부모 엔터티 = 부서, 자식 엔터티 = 사원 → 부서의 부서번호가 사원의 주식별자가 아닌 일반 속성으로 사용되었기 때문에 비식별자 관계이며 부모는 부서, 자식은 사원 엔터티이다. 사원 엔터티를 구성할 때에 부서번호가 필요하며, 사번이라는 주식별자 구성을 독립적으로 구성한다.
부모 엔터티 = 사원, 자식엔터티 = 구매신청 → 사원의 사번을 구매신청의 주식별자가 아닌 일반 속성으로 이용하였다.
D. 정규화
데이터의 일관성을 유지하고 데이터의 중복을 방지하며 데이터의 유연성을 유지하기 위해 데이터를 분해하는 과정
우선 용어를 우선 정리할 필요가 있다.
용어
설명
정규화(Normalization)
DBMS 테이블의 삽입, 삭제, 수정 과정에서의 이상(Anomaly) 현상의 발생을 최소화하기 위해 작은 단위의 테이블로 나눠가는 과정임
정규형(NF; Normal Form)
정규화된 결과물에 의해 도출된 데이터 모델이 갖춰야 할 특성을 만족하는 '정규화된 결과물'을 의미함
함수적 종속성(FD; Functional Dependency)
테이블의 특정한 컬럼 값(A)을 알고 있으면 다른 컬럼 값(B)을 알 수 있다고 가정할 때, 칼럼 B는 칼럼 A에 함수 종속성을 갖는다고 표현함
결정자(Determinant)
함수적 종속성에서 특정한 값을 의미함
다치 종속(MVD; MultiValued Dependency)
결정자 칼럼 A에 의해 칼럼 B의 값을 다수 알 수 있을 때, 칼럼 B는 칼럼 Z에 다치종속 되었다고 표현함
기본 테이블이 아래와 같으며 중복된 이름, 대학이 없다고 가정한다. 또한 1대학 당 1개의 소재지(시/도)를 갖는다.
제1정규화는 한 속성에 여러 개의 속성이 포함되어 있거나 같은 유형의 속성이 여러 개로 나눠져 있는 경우 해당 속성을 분리하는 것을 의미한다.
즉, 위의 테이블을 아래와 같은 테이블을 만드는 과정이다.
제1정규형을 만족함
제2정규화는 제1정규화를 만족시키고 PK가 아닌 모든 칼럼이 PK 전체에 종속하는 것을 의미한다. PK에 종속되지 않거나 PK 중에서 일부의 컬럼만 종속되는 칼럼이 있다면 이를 분리시켜야 한다.
제2정규형을 만족함
제3정규화는 제2정규화를 만족시키고 일반 속성 간에도 함수 종속 관계가 존재하지 않아야 한다. 이는 한 테이블에서 A → B, B →C 가 성립할 때 A →C 가 성립되는 것이 없어야 한다는 의미이다.
제3정규형을 만족함
PK에 해당하는 이름을 제외하면 다른 속성 간에는 종속관계가 발생하면 안된다. 그러나 대학명과 소재지(시/도)의 관계를 살펴보면 종속관계임을 알 수 있다. 이에 제3정규화를 위반한 경우라 볼 수 있고, 이를 해결하기 위하여 대학 정보만을 담고 있는 테이블을 따로 구성하여야 한다.
정규화 유형은 이보다 다양한 유형이 존재하지만 SQLD 시험에 주로 출제되는 제1정규화, 제2정규화, 제3정규화까지만 공부하기로 한다.
정리하자면,
제1정규화의 경우 모든 속성이 반드시 하나의 값을 가져야 하고, 한 속성에 여러 속성값을 부여하거나 같은 유형의 속성이 여러 개인 경우 해당 속성을 분리한다.(원자성 확보)
제2정규화는 주식별자에 완전하게 함수 종속되지 않은 속성을 분리하여 종속 관계를 구성한다.(부분적 함수 종속 제거)
제3정규화는 일반 속성간의 함수 종속성이 발생하지 않도록 분리한다.(이행적 함수 종속 제거)
본 프로젝트의 목표는 식중독 발생 확률을 예측하는 모델을 구축하여, 일반 시민과 정부 부처가 식중독을 사전에 예방할 수 있도록 지원하는 것이다. 필자는 데이터 분석 및 모델링을 담당하였으며, 주요 역할은 다음과 같다: 1) 데이터 수집 및 전처리: 식품의약품안전처의 Open API 데이터를 활용하여 식중독 현황을 분석하고, 관련 변수를 정리하였다. 2) 가설 설정: 식중독 발생에 지역축제, 사회 인프라가 영향을 미칠 것이라는 가설을 설정하였다. 관련 요인들을 정의하고, 이에 대한 데이터를 수집하여 모델링에 활용하였다. 3. 모델링 및 성과 평가: 여러 분류 모델을 비교하고, Random Forest 모델을 통해 70%대 중후반의 성능을 기록하여 식중독 발생 예측의 정확성을 높였다. 결과적으로, 지역별 식중독 발생 위험을 예측할 수 있는 모델을 성공적으로 구축하였으며, 이를 통해 맞춤형 예방 대책의 필요성이 제기되었다. 향후 통합 데이터와 일별 예측 모델을 통해 더욱 정교한 분석이 가능할 것으로 기대된다.
A. 배경
식중독(food poision)이란 식품위생법 제2조제14항에 따라 식품의 섭취로 인하여 인체에 유해한 미생물 또는 유독 물질에 의하여 발생하였거나 발생한 것으로 판단되는 감영성 또는 독소형 질환을 말한다. 일반적으로 구토, 설사, 발열 등의 증상을 나타내며 원인물질에 따라 잠복기와 증상의 정도가 다르게 나타난다. 비교적 가벼운 증상으로 나타지만, 면연력이 약한 어린이, 노인, 인산부의 경우에는 생명의 위협을 받을 수 있다. 2022년 6월 식품의약품안전처에서 발표한 보도자료에 따르면 2016년부터 2018년까지 식중독으로 인한 연간 손실비용이 연간 1조 8,532억원에 달하며 개인 손실비용이 1조 6,418억원(88.6%)을 차지한다고 밝혔다. 개인의 신체적 고통과 개인 비용 뿐만 아니라 사회적 비용을 줄일 필요성이 존재한다. 이에 이번 프로젝트에서는 기후, 인구밀도 등 다양한 외부 변수를 기반으로 지역별 식중독 발생확률을 예측하는 모델을 구축하고 일반시민 또는 관련 정부부처에서 식중독을 사전에 예방하는데 도움이 되고자 식중독 발생 예측 지도를 생성하고자 한다.
B. 데이터 준비
식품의약처안전처에서 제공하는 Open API 형식의 '지역별','원인물질별' 식중독 현황 데이터를 사용하였다. 지역별 데이터와 원인물질별 데이터를 결합할 수 있는 PK가 없어 정보공개청구 창구를 사용하여 지역별, 원인물질별, 원인시설별 식중독 발생 현황에 대한 자료를 요청하였지만, 식약처의 국정감사기간과 겹치며 기존 자료 수령일보다 10일 연기되어 자료 수령이 제 시간내에 불가능하게 되었다. 따라서 Open API 데이터를 각각 활용하여 2개의 테이블에 대한 데이터 전처리, 모델링 등이 이루어졌다.
식중독 지역별 현황
식중독 원인물질별 현황
OCCRNC_VIRS에서 원인물질은 총 15개로 집계된다. 이 중 의미를 부여할 수 없는 '원인 불명을 비롯하여 발생 비율이 1% 미만인 원인 물질들을 제외하고 9가지 주요 원인 물질을 선택하여 진행하였다.
범례
원인물질별 식중독 발생건수 비율
최종 원인물질별 식중독 발생건수
식중독균별 특성을 이해하고, 그에 따른 발생 확률을 증가시키는 요인에 대해 크게 3가지로 나누어 각 가설을 세워 추가 변수들에 대한 데이터를 수집하였다. 가설과 데이터는 다음과 같다.
요인
가설
관련 데이터
원인물질 발현 증가
고온 다습해질 수록 박테리아성 식중독 발생율은 증가할 것이다.
기후(온도, 습도, 해면 기압 등) 데이터
노출빈도 증가
인구 밀도가 높을 수록 식중독 발생율은 증가할 것이다.
인구수 데이터, 집단급식소 데이터
축제 등 이벤트 발생이 많으면 식중독 발생율은 증가할 것이다.
지역 축제 데이터, 황금연휴 데이터
예방/관리 소홀
사회 인프라가 잘 갖춰지지 않을 수록 식중독 발생율이 증가할 것이다.
소비자물가지수(CPI) 데이터
추가 변수들을 생성할 수 있는 데이터들을 '년', '월' , '지역' 등에 따라 각 데이터 테이블을 생성하였다.
지역별 데이터
원인물질별 데이터
다층분류 분석을 하고자 하였으나, 유의미한 결과가 나타나지 않아 발생 유무를 예측하는 방법으로 프로젝트 방향을 잡고, 이진 변수로 사용할 수 있는 칼럼들은 이진 변수로 사용하였다. 또한, 통계청의 데이터 이슈로 인해 추가 변수들의 데이터를 2022년까지 구할 수 있어 2002년부터 2022년까지 20년간의 데이터를 사용하였다. 세종특별자치시의 경우, 2012년 7월 충청도에서 출범한 지역이다 보니 다른 지역과 다르게 각 부처마다 데이터 적재시점이 다르다. 이에 따라 세종의 날씨 데이터와 CPI 데이터는 정합성과 적합성 평가를 통해 인근지역인 충청북도의 데이터를 이용해 선형회귀 모델로 보완하였다.
C. 데이터 분포 및 기본 특성
아래 그래프에서 볼 수 있듯 지역별, 원인물질별 데이터 불균형이 강하게 나타났다. 모델링 시 이를 고려하여, 오버샘플링(Oversampling) 혹은 SMOTE 기법을 사용할 수 있을 것이다.
지역별 히스토그램
원인물질별 히스토그램
식중독 발생에 대한 기본적인 통계를 살펴보면 다음과 같은 결과를 알 수 있다. 2002년부터 2022년까지 연도별 식중독 발생건수 및 환자 수를 살펴보면 특정 년도에 총환자수가 급증하는 것을 볼 수 있는데, 발생 건수 또한 급증한 것은 아니기에 대량 감염 사건이 발생했을 것이라 예상할 수 있다.
연도별 식중독 발생건수로 2018년 급증하는 환자수와 2020년 급락하는 환자수를 볼 수 있다.
예상과 같이 2018년 학교 급식에서 초코케이크 살모넬라 식중독으로 인해 약 2,200여명의 대규모 환자가 발생한 사건이 있었다. 또한, 2020년에는 COVID-19로 인한 보건정책 및 위생관리 강화로 환자수가 전년대비 36.88%나 감소하는 결과를 보인다.
연도별 식중독 발생건수 대비 환자 수
연도별 원인물질별 식중독 발생건수 대비 환자 수
연도별 지역별 발생 건수 변화
원인물질별 발생건수 대비 환자 수 비율
월별 원인물질별 총 발생 건수
2000년대 초반 이후 식중독 발생건수가 점점 줄어 들며, 전국적으로 발생 건수가 적었다. 2018년 일명 초코 케이크 사건이라 불리는 식중독 집단 감염 사건의 경우, 전국적으로 살모넬라균으로 인해 발생하였기 때문에 해당 시기에 급증한 그래프를 확인할 수 있다. 월별 식중독균별 발생건수를 살펴보면, 노로바이러스는 겨울철 정점에 도달하였다 점점 감소하여 여름에 최저 발생 건수를 기록하는 양상을 보인다. 반면, 병원성 대장균, 살모넬라, 그리고 캠필로박터제주니는 봄부터 증가하여 여름철에 최다 발생률을 보인다. 각 원인물질별에 따라 계절성이 나타난다는 것으로 해석할 수 있다. 지역별로 살펴보았을 경우, 서울-경기권이 전체 식중독 발생 건수의 35% 가량을 차지하였으며, 그 이후로는 부산, 경남, 강원, 인천 등의 순으로 나타났다. 서울-경기권이 타 지역에 비해 발생건수가 지속적으로 높게 나타나는 것을 알 수 있다.
D. 식중독 발생 확률 예측 모델링
분류 예측 모델링 워크 플로우
PyCaret을 활용하여 다양한 분류모델의 기본 성능을 평가하였다. 초기 모델 성능을 확인하고, 성능 개선을 목표로 4개의 후보 모델을 선정하였다. 지역별, 원인물질별 초기 좋은 성능을 보인 모델은 Random Forest, Gradient Boosting, LightGBM, XGBoost 이었다. 이 모델들은 기본적으로 성능 지표가 높게 나오기도 하였으나 비선형 패턴을 학습하는 능력, 변수 중요도 파악, 그리고 과적합을 효과적으로 제어할 수 있다.
본 프로젝트의 특이점은 일반적인 모델 성능평가 지표인 Accuracy 혹은 F1-Score보다 Recall(재현율)을 우선시하여 모델 성능을 평가하였다. Recall은 실제 양성 사례를 놓지지 않고 정확히 예측하는 능력을 나타내는 지표로, 특히 헬스케어 분야, 바이오 분야에서는 질병 진단이나 이상 징후를 조기에 감지하는데 중요한 역할을 한다. 우리 프로젝트의 주요 목적은 식중독 발생 가능성을 정확히 예측하여 사전에 예방 조치를 취할 수 있도록 하는 것이다. Recall 지표는 발생하지 않을 확률보다 발생할 확률을 잘 예측함으로 모델 성능을 평가하는데 적합하다고 판단할 수 있다.
먼저 선형회귀 모델 가능 여부 판단을 위해 선형회귀 모형의 기본가정인 선형성, 정규성, 등분산성, 독립성을 검토해본 결과, 사피로 검정에서 p-value 값이 0.05보다 작아서 정규성을 충족하지 않는 것으로 나타났으며, 다른 항목에서도 완전한 충족이 이루어지지 않아 비선형회귀모형, 시계열 모형, 분류 모형 등 다양한 모형을 시도하였다.
선형회귀모델 가능여부 검토
MinMax Scaler를 이용한 표준화 및 종속변수 BoxCox 변환
Random OverSampling 적용
회귀모형과 분류모형은 각 발생 건수와 식중독 발생여부를 종속변수로 모델링하였다. 처음 Train Data, Test Data로 분리시키고, MinMax Scaler와 BoxCox 변환을 통해 이상치의 영향은 줄이고 변수들 간의 비선형성을 개선하고자 하였다. 또한, 분류모델에서는 발생 여부를 나타내는 0과 1의 불균형으로 인해 모델이 하나의 결과에 편향되는 것을 방지하고자 SMOTE, Borderline-SMOTE 등 다양한 OverSampling 기법을 이용해 보았으나 Random OverSampling의 결과가 가장 좋았다. 이 후 GridSearchCV를 통해 모델별 validation data 기준 성능이 가장 우수한 하이퍼 파라미터를 선택하여 모델링을 실시하였다. 모델의 결과는 아래와 같다.
각 분석별 모델를 가장 설명하는 기법 선택
보시다시피 회귀모형, 시계열 모형, 딥러닝까지 다양한 모델들의 성능 평가 결과를 살펴보았을 때 분류모형을 제외한 다른 모형들 중 다중회귀 모형이 가장 좋은 성능을 보였다. 하지만 이 경우 최대 R2 score는 약 0.4로 전반적인 모델 성능이 모두 낮았다. 반면, 분류모형 중 가장 좋은 성능을 보인 Random Forest 분류모형은 최대 Accuracy 0.78로 양호한 성능을 보였다. 분류모형의 경우 기본 모형과 하이퍼 파라미터 튜닝모형의 성능 차이가 크지 않아 하이퍼 파라미터 튜닝 대신 데이터 분할 후 개별 모델링을 검토하였다.
지역별 식중독 발생 예측 모델링 결과원인물질별 식중독 발생 예측 모델링 결과
각 지역별로 예측모델링을 구축하였고, Oversampling, Feature Engineering, Hyperparameter tuning을 통해 70%대 중후반에서 90%대까지 성능이 제법 향상된 것을 확인할 수 있다. 다만, 광주, 세종과 같은 일부 지역은 데이터의 불균형이 너무 심하기 때문에 Oversampling을 하고 tuning을 해줘도 성능 향상에 한계가 있다.
변수 미래값 예측 모델 (Prophet 모델)
지역별 모델링과 동일하게 원인물질별 및 변수별로도 예측모델 구축을 완료하였다. 특히 변수의 미래 예측값은 모두 시계열 모델인 Prophet으로 모델링하였다. 시계열모델인 만큼 '유치원생의 비율', '소비자물가지수'와 같이 변동값이 크지 않은 변수들과 '평균온도', ' 해상기압', '습도'와 같이 계절성을 나타내는 변수의 R2 score 값이 대부분 1에 가깝게 몰려 있음이 확인된다. 그러나 황금연휴와 같이 특별한 주기성을 띄지 않는 변수들은 낮은 R2 score 값에 분포되어 있는 것으로 확인되었다. 해당 값들은 feature importance에서 비교적 낮은 중요도로 측정되는 변수로 모델 성능 저하에 지대한 영향을 미칠 것이라 확언하기 어렵다.
2023년 식중독 발생 예측 흐름
앞서 구축한 모델을 바탕으로 2023년 식중독 발생 확률을 예측하였다. 시계열 모델을 활용하여 2023년 1월부터 12월까지의 변수들의 값을 예측하여 생성하였다. 변수 예측값을 각각 지역별 모델과 물질별 모델에 입력하여 지역별 및 원인물질별 식중독 발생 예측 결과를 얻었다. 이미 2023년의 식중독 발생 기록을 보유하고 있기 때문에 예측 결과와 실제 발생 기록을 비교할 수 있다.
예측값 ROC Curve
통합된 예측값에 대한 ROC Curve를 도출한 결과 지역별 예측 모델의 Recall 값은 0.71, AUC는 0.72 값이 산출되었다. 원인물질별 예측 모델의 경우 Recall 값은 반올림하여 0.77, AUC 값은 0.74로 기록된다. AUC값은 실제 양성과 실제 음성을 잘 구별할 수 있다는 의미로, 모델이 얼마나 잘 예측하였는지를 나타내는 지표이다.
Open API에서 얻은 데이터 자체가 발생 식중독 건수를 월 단위로 집계하여 제공하고 있어 데이터의 n 수가 적고, 정확한 분석에 한계가 있다. 해당 상황에서 나름 준수한 성능을 보였다고 판단된다.
D. 인사이트
변수 중요도를 활용한 원인물질별 발생 위험 지역
분석 모형에서 추출한 모형별 변수 중요도(feature importance)를 이용하여 원인물질별 발생 위험 지역을 식별하였다. 모형별 상위 5대 중요변수가 유사한 지역과 원인물질을 서로 결합한 결과 부산은 병원성 대장균, 경상남도는 황색포도상구균과 유사성을 보였다. 해당 지역은 유사성을 보인 원인물질에 따라서 맞춤형 예방대책이 필요할 것이라고 진단할 수 있다. 다만, 이 시점에서 해당 모델이 지역, 시설, 원인물질 정보가 통합되어 있는 데이터셋을 기반으로 만들어진 것이 아니고, n수가 적다는 사실을 다시금 상기시킬 필요가 있다. 향후 통합데이터, 더 많은 정보를 담고 있는 데이터셋을 이용한다면 일별 데이터 예측하고, 추가 별수들의 일별 데이터를 적용하여 더욱 정교한 모델이 만들어 것이라 기대한다. 아울러 지금처럼 지역과 원인물질별 식중독 발생 예측 결과를 별개의 분석결과로 보는 것이 아닌, 서로 연동되어 '특정 월 또는 특정 환경에서는 어느 지역에서 어떤 원인물질의 발생확률이 증가한다.'와 같이 더욱 깊이 있는 예측 결과를 도출할 수 있을 것이다. 더 나아가 '그 지역에서 어떤 방법을 취해야한다.'와 같은 추가적인 인사이트를 유저들에게 제공할 수 있으리라 기대된다.
E. 대시보드 제작
이와 관련한 예측지도 대시보드를 제작하였다. 일반 국민, 보건 의료 실무자 및 관리자, 보건의료 정책 입안 담당자를 대상으로 현황 모니터링, 시뮬레이션 분석, 향후 12개월 예측, 총 3가지의 기능을 넣었다. 효과적인 정보전달을 위해 식중독 지도, 원인물질별 식중독 막대그래프, SHAP을 활용한 식중독 주요 요인 그래프, 식중독 추이 및 예측값 비교 선그래프 등을 사용하였으며 간결하고 명확한 정보 제공에 주안점을 두었다.
2024년 10월 11일, 코엑스에서 열린 2024 서울 빅데이터 포럼이 열렸다. AI와 빅데이터가 도시 문제 해결과 시민의 삶에 미치는 영향에 대한 논의가 이루어졌다. 해당 포럼의 목표는 서울 시민의 삶을 개선하고, 기술적인 혁신을 통한 정책 수립을 지원하는 것으로, 서울의 일상생활, 안전, 미래 도시 발전에 미치는 빅데이터와 AI의 영향력에 대한 토의하였다.
기조세션에서는 TU Delft의 Yanan Xin 교수와 NAVER 클라우드의 하정우, Microsoft의 Steve Shirkey가 AI와 빅데이터의 도시문제 해결, 안전 강화, 시민의 삶 개선 등에 대한 내용을 발표하였다. 이후 「데이터로 연결된 일상: 쾌적하고 편리한 서울 시민생활」, 「안전한 도시 서울: AI·빅데이터로 강화하는 도시 안전망」, 「데이터 · AI가 그리는 미래도시 서울」이라는 큰 주제로 나누어 발표와 토론이 이어졌다.
첫 세션, 「데이터로 연결된 일상: 쾌적하고 편리한 서울 시민생활」 에서는 서울의 대기질, 교통 데이터 분석 등을 활용하여 도출한 결과를 토대로 일상생활에서의 데이터 기반 편의성을 높이기 위한 방법들에 대한 논의가 오갔다.
두 번째 세션, 「데이터 · AI가 그리는 미래도시 서울」에서는 디지털 성범죄 분석 시스템, 건강 빅데이터 기반 치매 관리 등 다양한 사례연구를 소개하였다.
세 번째 세션, 「데이터 · AI가 그리는 미래도시 서울」은 데이터와 AI를 통한 서울의 미래 발전과 관련하여 통계 분야에서의 AI 도입 사례와 현재 주어진 도전 과제 등에 대해 논의하였다.
B. 발표 회고
가장 기억에 남는 발표는 기조세션의 하정우 센터장의 "소버린 AI를 넘어 더 나은 시민들의 삶을 위한 포용적 AI" 와 변형균 대표이사의 "AI로 진화하는 도시: 미래 도시의 설계" 이다.
최근 ChatGPT의 발전 속도는 가히 경이로울 정도다. 특히, 2023년에 출시된 GPT-4는 기존의 모델들에 비해 더 정교한 대화가 가능하고, 복잡한 문제 해결이 가능해졌다. 이제 곧 있으면 '아이언맨' 영화에 나오는 토니 스타크의 AI 비서 '자비스'가 탄생할 것 같다.
1. 소버린 AI를 넘어 더 나은 시민들의 삶을 위한 포용적 AI
하정우 센터장은 2024년 생성형 AI의 최신 트렌드를 소개하며, 멀티모달 AI, 온디바이스 AI, 오픈소스 기술이 시민들의 일상을 어떻게 변화시킬 것인지에 대하여 발표하였다. 기술의 발전은 AI 시스템의 접근성을 높이고 사용자 친화적으로 만들었다. 그러나 글로벌 AI 환경은 점점 더 치열해지는 경쟁 속에 있으며, 자국의 문화적 가치에 맞는 AI 기술을 개발하고자 노력하고 있다고 한다. 이는 '소버린 AI' 로 이어진다. 네이버 CLOVA에 따른 소버린 AI(Sovereign AI) 란, 국가 또는 특정 정부가 독립적으로 개발하고 관리하는 인공지능 시스템을 지칭하는 개념이다. 특히, 데이터 주권(Data Sovereignty)과 국가 안보 측면에서 중요하게 다뤄지고 있으며, 외부 의존성을 최소화하고 국가의 전략적 이익을 보호하며 민감한 정보와 데이터의 통제권을 확보하는 것이 핵심 목표이다. 다시 말해 데이터를 국가내에서 보호하고 관리하는 것으로, 국가 또는 정부가 자국민의 데이터와 AI 시스템에 대한 통제권을 가지려는 의도를 가졌다고 볼 수 있다. 이와 더불어 네이버가 소버린 AI를 개발하며 적용사례를 소개하였다. 그와 동시에 특정국가를 위한 AI에 그치지 않고, 글로벌 문화 다양성과 포용성을 촉진하는데 중요한 개념으로 모든 국가가 협력하여 모든 시민에게 유익한 AI 기술을 개발할 수 있음을 강조하며 발표가 끝이 났다.
또한, 네이버의 AI 기술의 발전과 함께 이를 뒷받침하기 위한 데이터 센터 확장 계획을 발표하며. 대규모 데이터를 안정적으로 처리할 수 있는 인프라의 중요성에 대해서도 이야기하였다. AI 기술의 발전에 따라 빠르고 안정적인 데이터 처리 인프라는 필수적이다. 그러나 데이터 센터의 확장에는 단순한 기술적 도약뿐만 아니라 사회적 책임도 함께 포함해야한다 생각한다. 한국토지신탁에서 데이터 센터 개발 사업을 지켜보며 알게 된 사실은 엄청난 전력을 소모한다는 것이다.(전력량을 수치로 보며 받았던 충격을 잊을 수 없다.) 이로 인해 온실가스 배출과 같은 환경 문제를 야기할 수 있다. 그렇기에 기업의 이익뿐 아니라 데이터 센터 건립으로 발생하는 사회적 비용에 대하여 함께 고민해야 한다. 지속가능한 도시, 인프라를 목표로 삼고 있다면, 정부는 이를 뒷받침할 수 있는 정책적 방향성을 제시해야 한다고 본다. AI가 진정 도시문제를 해결할 수 있다면, 정부는 방향을 제시하고 기업은 책임을 다하며, 시민은 참여와 감시를 통해 더 나은 도시를 만들도록 협력해야 한다.
2. AI로 진화하는 도시: 미래 도시의 설계
변형균 대표이사는 AI가 도시의 교통, 환경, 자원 관리 등의 도시 문제 해결에 핵심적인 역할을 한다고 이야기하였다. AI를 통해 교통 혼잡 문제를 해결하고 에너지 사용을 최적화하는 시스템의 필요성을 강조하며, 글로벌 스마트 시티의 사례를 소개하였다. 흔히 AI와 스마트시티에 대한 내용임에도 불구하고 이 발표가 잊혀지지 않는 이유는 현재 진행 상황과 우리가 꿈꾸는 도시의 그 간극에 대해 이야기하고 있기 때문이다. 스마트 교통 시스템과 예측 인프라 유지관리와 같은 AI의 초기 혁신단계를 목격하고 있다. 그러나 기술발전과 사회적 적응의 차이로 인해 AI 기반 도시 유토피아의 완전한 실현에는 여전히 시간이 필요함을 설명한다. 새로운 기술이 더 효율적이고 지속 가능한 도시를 만들기 위한 토대를 마련하고 있지만, 오늘날의 스마트 시티와 미래의 AI 통합 대도시 사이에는 여전히 해결해야하는 문제들이 남아있다. AI기술이 도시 인프라의 효율성을 극대화하고, 궁극적으로 지속 가능한 도시를 만드는데 기여할 것이라는 그의 말이 현실적으로 들렸다. 변형균 대표이사는 앞으로의 6개월 동안의 AI 발전이 이전 6개월의 변화와는 다를 것이라 말하며, AI의 발전이 점진적이지만 근본적으로 도시를 재편하고, 인간의 삶을 향상시키는 방향으로 나아갈 것이라고 전망하였다.
C. 마무리
이번 포럼은 서울이 빅데이터와 AI를 활용하여 시민들의 삶의 질을 개선할 수 있는 방안에 대해 논의하고, 정책, 거버넌스, 기술 혁신의 중요성을 강조하며 공공 및 민간 부문이 함께 협력할 수 있는 장을 마련하였다. 나에게도 도시 속에 AI가 어떤 방식으로 활용되고 있는지 알 수 있는 좋은 기회였다. 데이터 분석을 기반으로 진행된 다양한 연구사례들을 보면서 현재 공부 중인 데이터 분석이 실제 어떻게 쓰이고 있는지, 결과를 살펴보며 어떤 생각, 통찰을 통해 결론을 낼 수 있는지에 대해 배울 수 있었다.
우리 도시의 미래를 낙관적으로 바라보는 관점이 인상적이었다. 문제를 분석하고 이를 해결하고자 노력하는 이들이 많아 안심이 되었다. 정책과 기술의 발전 간의 조화가 얼마나 중요한지에 대해 생각해볼 수 있는 귀한 시간이었다.
평균과 분산이 시간이 지나도 일정하지 않은 비정상 시계열로, 시간이 지남에 따라 무작위로 이동하는 경로를 설명하는 수학적 모델이다. 공식은 아래와 같다.
현재 값은 과거 값, 상수, 백색소음의 입력값으로 결정된 함수이며, 현재 값이 과거 정보와 랜덤한 변동의 영향을 받는다.
C. 정상성(Stationarity)
1. 정상성의 정의
시계열의 통계적 성질이 시간에 따라 변하지 않는 상태를 의미한다. 시계열 데이터에서 정상성을 가정하거나 내포하면 모델링과 예측 가능성이 좋아진다. 통계적 성질이란 데이터의 중앙값, 분포, 변동성, 상관성 등의 특성을 나타내며 데이터를 분석하는데 있어 중요한 역할을 한다.
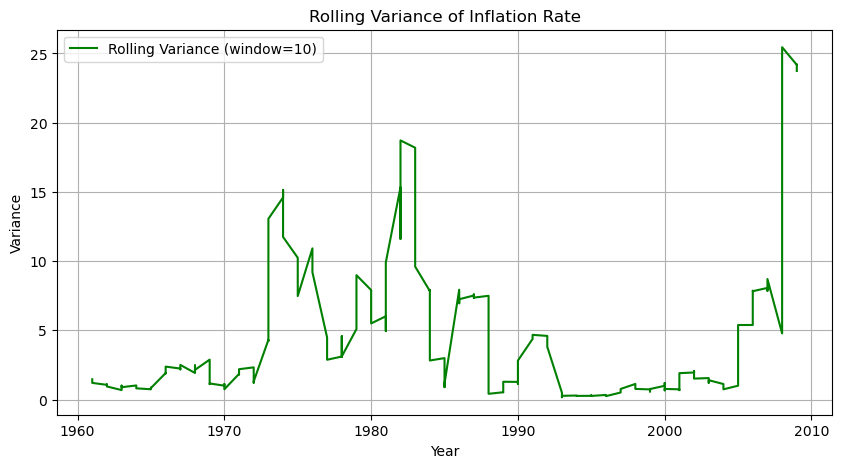
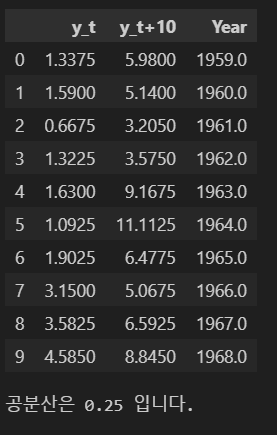
Nelson-Plosser의 연 평균 물가상승률 데이터를 통해 알아보고자 한다.
# 연도별 평균 물가 상승률 계산
import statsmodels.api as sm
import pandas as pd
import matplotlib.pyplot as plt
data = sm.datasets.macrodata.load_pandas().data
inflation_rate_df = pd.DataFrame({
'Year': data['year'],
'Inflation Rate': data['infl']
})
inflation_rate_yearly_avg = inflation_rate_df.groupby('Year').mean().reset_index()
# 데이터프레임 출력
display(inflation_rate_yearly_avg.loc[:5,:])
# 연도별 평균 물가 상승률 시각화
plt.figure(figsize=(10, 5))
plt.plot(inflation_rate_yearly_avg['Year'], inflation_rate_yearly_avg['Inflation Rate'], label='Average Inflation Rate')
plt.title('Average Inflation Rate per Year')
plt.xlabel('Year')
plt.ylabel('Inflation Rate')
plt.grid(True)
plt.show()
2. 정상성 시계열 조건
1) 시계열의 평균이 시간에 따라 변하지 않고 일정함
y_t의 기댓값이 시간t에 관계 없이 상수 μ로 일정함
시간이 변해도 데이터가 일정한 평균 주위를 중심으로 변동한다고 볼 수 있다.
2) 시계열의 분산이 시간에 따라 일정함
모든 시점에서 동일한 상수 분산을 나타냄
시간에 관계없이 일정한 변동성을 갖는다.
3) 시계열의 두 시점간 공분산이 시간(t)에 의존하지 않고 시간의 차(h)에만 의존함
시점 t와 t+h 사이의 공분산이 시차 h에만 의존하고, 특정 시점 t에는 의존하지 않음
공분산은 두 확률 변수의 선형 관계를 나타내는 값이며, 시점 t의 데이터와 t+h 시점의 데이터 사이의 공분산이 시간 t에 무관하게 일정하다는 의미를 갖는다.
3. 정상성 확보를 위한 데이터 변환 기법
1) 위의 데이터는 평균, 분산, 공분산이 모두 변동하고 있으며, 이는 비정상성을 띈다고 볼 수 있다.
2) 평균 안정화
- 차분(Diffencing)
추세, 계절성을 제거하기 위한 방법으로, 특정 시점과 그 시점 사이 발생하는 변화를 계산한다.
- 이동 평균 평활화(Moving Average Smoothing)
단기적인 변동성을 제거하고 전체적인 추세를 더 명확히 볼 수 있다.
3) 분산 안정화
- 로그 변환
분산을 줄이기 위한 변환으로, 데이터의 스케일이 너무 커지거나 변동성이 큰 경우 유용하다.
- 제곱근 변환
로그효과와 유사하게 분산을 줄이는 효과가 있으며 데이터가 극단적으로 변동하는 경우 유용하다.
D. 마무리
계속해서 비정상성을 나타낸다.
E. 20240926 내용 추가
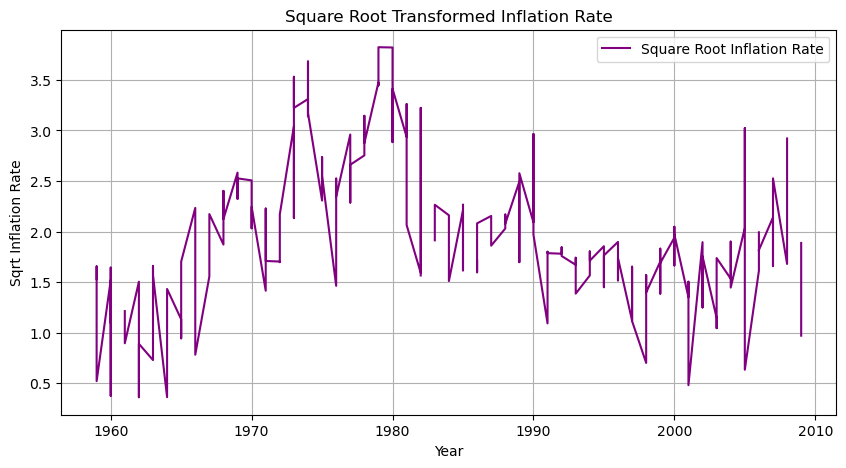
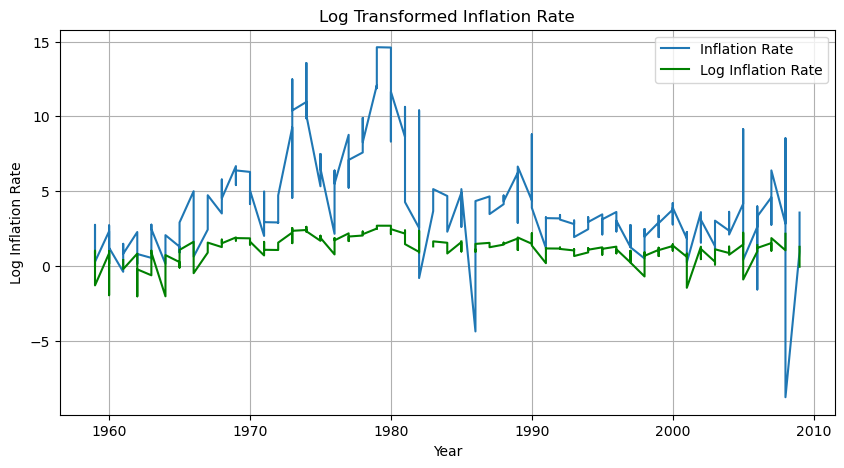
정상성 확보를 위한 데이터 변환 기법을 사용하였음에도 불구하고 비정상성을 나타내는 것 같아 기존 그래프와 비교하였다.
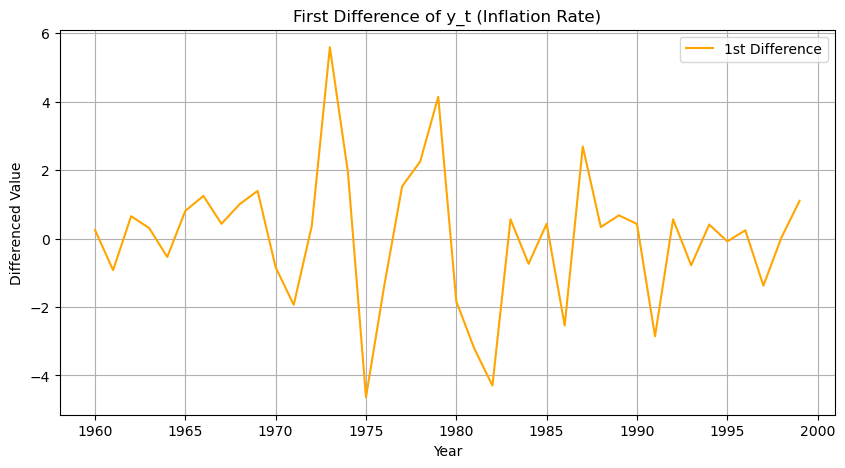
1. 차분 적용
주황색 선을 보면 파란 선보다 일정하다.
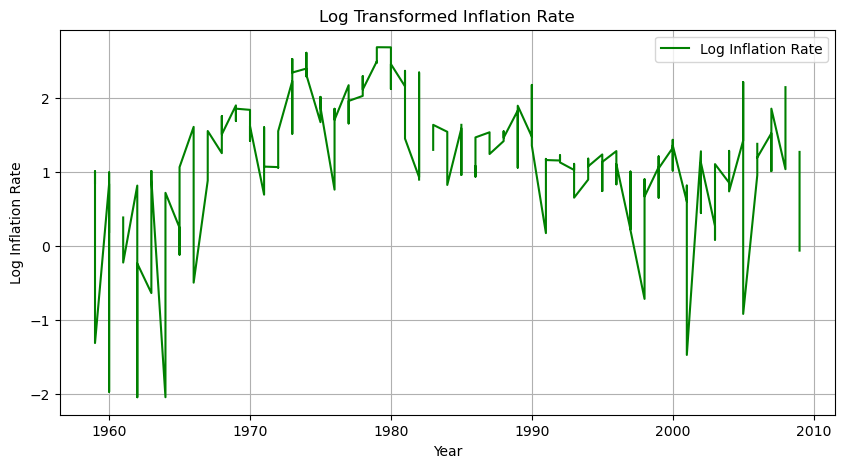
2. 로그 변환
초록색 선이 파란 선보다 일정하다.
3. 제곱근 변환
보라색 선이 파란색 선보다 일정하다.
각 방법을 사용하였을 때 확실히 이 전보다 정상성을 갖는 것을 확인할 수 있다.
전에 그린 그래프의 Y축 값이 일정하지 않았기 때문에 그래프가 계속 널뛰는 것처럼 보였던 것이었다. 그래프를 그리면 축 확인하자.
해당 데이터는 분산 안정화를 시켰을 때 정상성을 갖는 것으로 보인다. 그 이유가 궁금해진다.
프로젝트를 하면서 가장 많이 본 에러문구는 Out Of Memory(OOM) 이다. 긴 시간 셀을 실행시켜 나온 메모리에러를 볼 때마다 절망적이었다. 그러나 빅데이터를 다루는 사람이라면 메모리 관리도 하나의 능력이다.
1) 메모리의 정의
'메모리(Memory) = 기억장치' 이다. 크게 RAM 과 Disk(SSD)로 나눌 수 있고, Disk(SSD)는 우리가 익히 잘 아는 저장공간을 의미한다. 장기적으로 데이터를 보관하는 공간으로 전원이 꺼져도 데이터는 사라지지 않는다.
2) RAM의 정의
'Random Access Memory' 로 사용자가 자유롭게 읽고 쓰고 지울 수 있는 기억장치를 의미한다. '주 기억장치'로 분류되며, '책상', '도마' 등으로 비유된다. 램이 많으면 한 번에 많은 일을 할 수 있으며, 이는 책상이 넓으면 그 위에 여러가지 물품을 올려놓을 수 있고, 그 물품을 다시 회수하면 물품이 있었다는 기록은 사라지기 때문이다.
램은 성능이 좋을수록, 용량이 클수록 더 많은 일을 빠르게 수행할 수 있기 때문에 다다익램이라고도 한다.
2. 데이터가 메모리에 저장되는 방법
메모리에는 수 많은 비트(0 혹은 1)가 저장되고 각각의 비트는 고유한 식별자(Unique identifier)를 통해 위치를 사용할 수 있다.
1) 정수(Integers)
컴퓨터에서는 이진법으로 표현하며, 얼마나 많은 메모리를 할당할 것인지를 말한다. 더 많은 메모리를 할당할 수록, 더 큰 숫자를 담을 수 있다.
택시기사들에게 전달할 파일로, 코로나와 같은 팬데믹 상황이 왔을 때 대비할 수 있게 정보를 전달하고자 한다 상세: 2019년부터 2024년까지 매년 12월 데이터를 통해 뉴욕 옐로우 택시 이용 패턴을 확인하여 택시 기사들의 수익 극대화를 도모한다.
B. 데이터 선택
뉴욕은 미국의 최대 도시이자 가장 유명한 관광지이다. 뉴욕의 슬로건이 ‘The City that Never Sleeps’ 절대 잠들지 않는 도시인 것만 보아도 한눈에 알 수 있다. 어떤 계절이건 늘 관광객으로 가득하다. 특히 12월의 뉴욕은 크리스마스를 보내는 사람들, 새해 카운트를 세고자 하는 사람들로 가득찬다. 특정 기간, 시간에 많은 사람들이 모이는 곳에서의 택시 운행 행태를 파악하기 위하여 2019년부터 2023년까지 5개년치의 12월 데이터를 선택하였다.
세부사항: NYC 에서 제공하는 택세 데이터 중 예약없이 길거리에서 잡아 탑승할 수 있는 옐로우 택시 데이터를 기준으로 분석하고자 한다
C. 데이터 전처리
기초 통계량 및 각 데이터 별 수치를 살펴보고 이상치, 결측치 값 처리 방법을 정하였다.
기준: 각 년도 12월 데이터가 아닌 값, 승객 및 여행 정보에서 딕셔너리에 기재되어 있지 않은 값 처리, 결제 및 요금의 음수값 처리 및 이에 따른 총 결제액 재계산. 등등
1. 1차 전처리 코드
import pandas as pd
# 파일 경로 리스트
file_paths = [
'yellow_tripdata_2019-12.parquet',
'yellow_tripdata_2020-12.parquet',
'yellow_tripdata_2021-12.parquet',
'yellow_tripdata_2022-12.parquet',
'yellow_tripdata_2023-12.parquet'
]
# 파일명에 해당하는 연도 리스트
years = [2019, 2020, 2021, 2022, 2023]
# 전처리 함수 정의
def preprocess_and_save(df, year):
# 2023년 파일일 경우 'Airport_fee' 컬럼명을 'airport_fee'로 변경
if year == 2023:
df.rename(columns={'Airport_fee': 'airport_fee'}, inplace=True)
# 컬럼 타입 변경
df['tpep_pickup_datetime'] = pd.to_datetime(df['tpep_pickup_datetime'])
df['tpep_dropoff_datetime'] = pd.to_datetime(df['tpep_dropoff_datetime'])
# 연도 필터링: tpep_pickup_datetime과 tpep_dropoff_datetime 모두 해당 연도에 맞는 데이터만 남기기
df = df[(df['tpep_pickup_datetime'].dt.year == year) & (df['tpep_dropoff_datetime'].dt.year == year)]
# 결측치 처리
df = df.dropna(subset=['passenger_count', 'RatecodeID', 'store_and_fwd_flag', 'congestion_surcharge'])
df = df[df['payment_type'] != 0]
# 승객 및 여행 정보 이상치 전처리
df = df[df['VendorID'] != 5]
df = df[df['tpep_pickup_datetime'].dt.month == 12]
df = df[df['tpep_dropoff_datetime'].dt.month == 12]
df['passenger_count'] = df['passenger_count'].apply(lambda x: 4 if x >= 5 else x)
df = df[df['trip_distance'] >= 0]
# 결제 및 요금 정보 전처리
df = df[df['payment_type'].isin([1, 2])]
df = df[df['total_amount'] > 0]
df['mta_tax'] = 0.5
df['improvement_surcharge'] = 0.3
df['congestion_surcharge'] = df['congestion_surcharge'].apply(lambda x: 2.5 if x == -2.5 else x)
df = df[df['fare_amount'] > 0]
df['extra'] = df['extra'].abs()
# 승객수 0명인 경우 평균값 2명으로 대치
df['passenger_count'] = df['passenger_count'].replace(0, 2)
# RatecodeID 값이 6 이하인 것만 유지
df = df[df['RatecodeID'] <= 6]
# tip_amount: 0 이상인 값만 유지
df = df[df['tip_amount'] >= 0]
# tolls_amount: 0 이상인 값만 유지
df = df[df['tolls_amount'] >= 0]
# total_amount 값 변환
df['total_amount'] = df['fare_amount'] + df['extra'] + df['mta_tax'] + df['improvement_surcharge'] + df['tolls_amount'] + df['congestion_surcharge'] + df['airport_fee'].fillna(0)
# CSV 파일로 저장
csv_file_name = f'D:/Bootcamp/3rd_project/yellow_taxi_data_{year}.csv'
df.to_csv(csv_file_name, index=False)
# 저장 완료 메시지 출력
print(f"CSV 파일 저장 완료: '{csv_file_name}'")
# 모든 파일에 대해 전처리 및 저장 실행
for file_path, year in zip(file_paths, years):
df = pd.read_parquet(file_path)
preprocess_and_save(df, year)
2. 문제 사항 발견
1) trip distance 값과 total amount 값에 처리되지 않은 이상치 발견
실제값에 매우 큰 값들이 있고, 데이터는 제대로 예측하지 못함.
2) Trip distance 값, Total amount 값에서 극단값 발견
위치 정보 전처리 방법 가장 멀리 있는 레코드 두개의 거리 측정 후 그 거리 이상의 값 삭제 처
해당 방법으로 삭제 처리하기 위하여 NYC에서 제공하는 Yellow Taxi Zone 데이터 활용
기존 데이터와 zone의 위도,경도 데이터를 병합한 후 승차 위치를 기준으로 지리적 거리를 측정하였다.
# LocationID와 위도/경도 정보가 들어있는 location_df 로드
location_df = pd.read_csv('taxi_zones_latlong.csv') # LocationID, Latitude, Longitude가 포함된 데이터
# PULocationID를 기준으로 위도와 경도를 병합 (픽업 지점)
df = df.merge(location_df[['LocationID', 'Latitude', 'Longitude']], left_on='PULocationID', right_on='LocationID', how='left')
df.rename(columns={'Latitude': 'PULatitude', 'Longitude': 'PULongitude'}, inplace=True)
df.drop(columns=['LocationID'], inplace=True)
# DOLocationID를 기준으로 위도와 경도를 병합 (드롭오프 지점)
df = df.merge(location_df[['LocationID', 'Latitude', 'Longitude']], left_on='DOLocationID', right_on='LocationID', how='left')
df.rename(columns={'Latitude': 'DOLatitude', 'Longitude': 'DOLongitude'}, inplace=True)
df.drop(columns=['LocationID'], inplace=True)
# 병합 후 NaN 값이 있는지 확인
print(df.isnull().sum())
# NaN 값이 있는지 확인하고 제거
df_cleaned = df.dropna(subset=['PULatitude', 'PULongitude', 'DOLatitude', 'DOLongitude'])
from geopy.distance import geodesic
# 지리적 거리를 계산하는 함수 정의 (마일 단위로 계산)
def calculate_distance_miles(pickup_coords, dropoff_coords):
return geodesic(pickup_coords, dropoff_coords).miles # 마일 단위로 계산
# 픽업과 드롭오프 지점의 좌표로부터 거리 계산
df_cleaned['distance_miles'] = df_cleaned.apply(
lambda row: calculate_distance_miles((row['PULatitude'], row['PULongitude']),
(row['DOLatitude'], row['DOLongitude'])), axis=1)
# 가장 멀리 떨어진 두 지점 찾기
max_distance_record = df_cleaned.loc[df_cleaned['distance_miles'].idxmax()]
max_distance = max_distance_record['distance_miles']
print(f"가장 멀리 있는 두 지점 사이의 거리: {max_distance} miles")
# 그 거리 이상인 레코드를 필터링해서 제거
df_filtered = df_cleaned[df_cleaned['distance_miles'] <= max_distance]
print(f"필터링 후 남은 레코드 수: {len(df_filtered)}")
df_filtered.to_csv("df_filtered_distance.csv")
그러나 1시간이 지나도 해당 결과를 보지 못하였고, 반복해서 MemoryError가 발생하였다.
이에 맨해튼 거리방법으로 해당 극단값을 해결해보고자 하였다.
5) 맨해튼 거리
# 맨해튼 거리 계산
df['manhattan_distance'] = abs(df['Latitude_pickup'] - df['Latitude_dropoff']) + abs(df['Longitude_pickup'] - df['Longitude_dropoff'])
# 최대 거리 설정
max_distance = df['manhattan_distance'].max()
# 맨해튼 거리 이상인 레코드를 필터링하여 제거
df_filtered = df[df['manhattan_distance'] <= max_distance]
df = df_filtered.copy()
# PULocationID가 location_df에 없는 경우 확인
pulocation_missing = df[~df['PULocationID'].isin(location_df['LocationID'])]
# DOLocationID가 location_df에 없는 경우 확인
dolocation_missing = df[~df['DOLocationID'].isin(location_df['LocationID'])]
# 결과 출력
print(f"LocationID가 없는 PULocationID 레코드 수: {len(pulocation_missing)}")
print(f"LocationID가 없는 DOLocationID 레코드 수: {len(dolocation_missing)}")
# PULocationID가 location_df에 없는 고유 값 확인
missing_pulocation_ids = pulocation_missing['PULocationID'].unique()
print(f"LocationID가 없는 PULocationID 목록: {missing_pulocation_ids}")
# DOLocationID가 location_df에 없는 고유 값 확인
missing_dolocation_ids = dolocation_missing['DOLocationID'].unique()
print(f"LocationID가 없는 DOLocationID 목록: {missing_dolocation_ids}")
# 제외할 LocationID 목록
exclude_locations = [264, 265, 57, 105]
# PULocationID와 DOLocationID에서 제외하는 필터링 조건 적용
df = df[~df['PULocationID'].isin(exclude_locations) & ~df['DOLocationID'].isin(exclude_locations)]
LocationID를 살펴보고 승차 및 하차 위치 코드에 없는 번호를 찾아 삭제 처리하였다.
C. 분석 모형
- 목적: 택시기사에게 최대 수익을 가져다 줄 수 있는 승객의 탑승 위치를 예측하고자 한다.
- 기본 형식 지정
df = pd.read_csv('yellow_taxi_data_mega_df.csv')
# 컬럼 타입 변경
df['tpep_pickup_datetime'] = pd.to_datetime(df['tpep_pickup_datetime'])
df['tpep_dropoff_datetime'] = pd.to_datetime(df['tpep_dropoff_datetime'])
# 'pickup_day' 열을 새로 생성 (요일 정보 추출)
df['pickup_day'] = df['tpep_pickup_datetime'].dt.dayofweek # 0: 월요일, 6: 일요일
df['hour'] = df['tpep_pickup_datetime'].dt.hour
1. KMeans를 활용한 분석
- 모델 사용 이유: 승차 위치 그룹화를 통해 효율적인 운영 전략을 도출하기 위해 최적의 승차 위차를 찾고자 함.(위치 기반 시스템을 개선하고자 함)
1) KMeans 코드
# 위도와 경도를 이용한 클러스터링
locations = df[['Latitude', 'Longitude']].dropna().drop_duplicates()
# KMeans 클러스터링 적용
kmeans = KMeans(n_clusters=10, random_state=42).fit(locations)
# 클러스터링 대상이 된 데이터프레임의 인덱스 추출 (dropna를 고려한)
valid_indices = df[['Latitude', 'Longitude']].dropna().index
# 각 승차 위치에 클러스터 할당 (dropna된 행에 대해 클러스터 예측)
df.loc[valid_indices, 'cluster'] = kmeans.predict(df.loc[valid_indices, ['Latitude', 'Longitude']])
# 특정 시간대와 요일에 대해 클러스터별 평균 수익 계산
filtered_data = df[(df['hour'] == hour_input) & (df['pickup_day'] == day_input)]
# NaN 값을 제거한 후, 클러스터별 평균 수익을 계산
cluster_revenues = filtered_data.groupby('cluster')['total_amount'].mean().reset_index()
# 수익이 높은 순으로 클러스터 정렬
cluster_recommendations = cluster_revenues.sort_values(by='total_amount', ascending=False)
# 상위 3개의 클러스터 추천
top_clusters = cluster_recommendations.head(3)
print("추천 클러스터:", top_clusters)
# 해당 클러스터의 대표 승차 위치 추천
for cluster in top_clusters['cluster']:
location_in_cluster = df[df['cluster'] == cluster][['PULocationID', 'Latitude', 'Longitude']].drop_duplicates().head(5)
print(f"클러스터 {cluster}의 추천 승차 위치:")
print(location_in_cluster)
# 산점도: 위도와 경도를 기준으로 클러스터에 따라 색을 다르게 표현
sns.scatterplot(
x='Longitude',
y='Latitude',
hue='location_cluster', # 클러스터에 따라 색상을 다르게 설정
data=filtered_data, # 데이터프레임을 random_sample_100k로 수정
palette='viridis',
legend='full'
)
# 클러스터 중심 계산
centroids = filtered_data.groupby('location_cluster')[['Latitude', 'Longitude']].mean().reset_index()
# 클러스터 중심에 마커 추가
plt.scatter(
centroids['Longitude'],
centroids['Latitude'],
s=100, # 마커 크기
c='red', # 마커 색상
label='Centroids', # 범례 이름
marker='X' # 마커 형태 (X 모양으로 표시)
)
# 그래프 설정
plt.title('Cluster Visualization of Taxi Pickups')
plt.xlabel('Longitude')
plt.ylabel('Latitude')
plt.legend(title='Cluster')
# 그래프 출력
plt.show()
1. Cluster 0 (보라색): - 위치: 대부분의 데이터 포인트가 뉴욕의 서쪽에 위치해 있다. 주로 로어 맨해튼 또는 허드슨 강 근처일 가능성이 있다. - 특성: 이 클러스터는 다른 클러스터들보다 좀 더 넓은 범위에 퍼져있으며, 도시 외곽에 더 가깝다.
2. Cluster 1 (파란색): - 위치: 뉴욕 시 맨해튼의 중심부 근처에 집중되어 있다. - 특성: 이 클러스터는 맨해튼 북부 또는 중부 지역의 택시 픽업 위치를 나타낼 수 있다. 도시 내에서 더 밀집된 픽업 패턴을 보여주고 있다.
3. Cluster 2 (녹색): - 위치: 뉴욕 시의 동쪽, 특히 퀸즈나 브루클린으로 추정되는 지역에서 주로 발생하는 픽업을 나타낸다. - 특성: 이 군집은 도시 중심에서 떨어진 곳에서 주로 형성된 클러스터이다.
4. Cluster 3 (노란색): - 위치: 맨해튼 남부와 허드슨 강에 가까운 지역. - 특성: 맨해튼의 하단부에서 매우 밀집된 픽업 위치가 많으며, 뉴욕의 핵심 중심지에 있는 클러스터일 가능성이 크다.
5. 군집 특성 분석: - 지리적 범위: 각 클러스터가 나타내는 위치에 따라 주요 택시 픽업 지역의 밀집도를 보여준다. Cluster 0과 Cluster 2는 도시 외곽에서 픽업되는 빈도가 높은 반면, Cluster 1과 3은 맨해튼의 중심부에서 발생하는 픽업이다. - 클러스터 중심: 각 클러스터의 중심은 군집의 평균적인 픽업 위치를 나타내며, 픽업 활동이 활발한 지역을 확인하는 데 유용하다.
3. Random Forast Regressor 를 활용한 분석
- 모델 사용 이유: 여러 개의 의사결정트리를 사용해 과적합 방지 및 예측 성능을 향상하기 위해 사용함.
- 회귀분석: 운행 거리와 총 수익간의 관계를 분석하고 회귀 직선을 시각화 하기 위해 진행함.
1) 머신러닝 모델 코드
# 모델에 사용할 특성
features = random_sample_100k[['pickup_day_of_week', 'pickup_hour', 'location_cluster', 'manhattan_distance', 'total_amount']]
target = random_sample_100k['RatecodeID']
# 데이터를 학습용과 테스트용으로 분할
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2, random_state=42)
# 랜덤 포레스트 모델로 학습
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 테스트 데이터를 통해 예측
y_pred = rf_model.predict(X_test)
# 모델 성능 평가 (RMSE)
mse = mean_squared_error(y_test, y_pred)
rmse = mse ** 0.5
print(f'평균 제곱근 오차(RMSE): {rmse:.2f}')
# 평균 제곱근 오차(RMSE): 13.81
- Accuracy 0.99인 값이 측정되었다.
2) 실제값과 예측값의 산점도
수치가 작은 값들은 잘 맞지만, 적절한 모델은 아닌 것으로 보인다.
4. LightGBM 사용하여 재분석
# 클러스터링을 위한 위도, 경도 기반 KMeans 적용
kmeans = KMeans(n_clusters=4, random_state=42) # 클러스터 수는 4로 설정
df['location_cluster'] = kmeans.fit_predict(df[['Latitude', 'Longitude']])
# 추가 피처로 수익성 관련 칼럼 선택
X = df[['pickup_day_of_week', 'pickup_hour','pickup_latitude','pickup_longitude','dropoff_latitude','dropoff_longitude']]
y = df['total_amount']
# 데이터 분리 (학습 데이터와 테스트 데이터로 나누기)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 훈련 및 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# LightGBM 회귀 모델 정의
lgb_model = lgb.LGBMRegressor(
n_estimators=1000,
learning_rate=0.05,
max_depth=10,
random_state=42,
n_jobs=-1
)
# 모델 학습 - early stopping 및 학습 진행 상황 출력
lgb_model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric='rmse', # 평가 메트릭 설정
callbacks=[
lgb.early_stopping(stopping_rounds=100), # early stopping 콜백
lgb.log_evaluation(50) # 50번마다 학습 로그 출력
]
)
# 예측
y_pred = lgb_model.predict(X_test)
# 모델 성능 평가 (RMSE)
rmse = mean_squared_error(y_test, y_pred, squared=False)
print(f"RMSE: {rmse}")
# 예측값이 연속형이므로 회귀 평가지표 사용
print("RMSE:", mean_squared_error(y_test, y_pred, squared=False)) # Root Mean Squared Error
print("MAE:", mean_absolute_error(y_test, y_pred)) # Mean Absolute Error
print("R² Score:", r2_score(y_test, y_pred)) # R^2 Score (결정 계수)
# RMSE: 6.15423934688325
# MAE: 3.534872188639418
# R² Score: 0.8479843617006366
nyc_map = folium.Map(location=[40.7128, -74.0060], zoom_start=12)
for index, row in top_locations_with_coords.iterrows():
folium.Marker([row['Latitude'], row['Longitude']],
popup=f"Location ID: {row['LocationID']}").add_to(nyc_map)
- 해당 위치와 클러스터의 중심이 비슷한 것으로 보아 Top 20 곳 혹은 Top10 위치로 범위를 좁혀 진행하였다.
4. 승하차 지역 중 가장 많은 지역 Top10 데이터를 활용한 머신러닝
1) 데이터 준비
# Top10 안에 들어가는 값만 추출
filtered_data = df[(df['PULocationID'].isin(top_locations_with_coords['LocationID'])) |
(df['DOLocationID'].isin(top_locations_with_coords['LocationID']))]
filtered_data.describe()
2) 클러스터링을 위한 위도, 경도 기반KMeans 적용 및 피쳐, 타겟 변수 변경
# 클러스터링을 위한 위도, 경도 기반 KMeans 적용
kmeans = KMeans(n_clusters=4, random_state=42) # 클러스터 수는 4로 설정
df['location_cluster'] = kmeans.fit_predict(df[['Latitude', 'Longitude']])
# 추가 피처로 수익성 관련 칼럼 선택
X = df[['pickup_day_of_week', 'pickup_hour','pickup_latitude','pickup_longitude','dropoff_latitude','dropoff_longitude']]
y = df['total_amount']
# 훈련 및 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# LightGBM 회귀 모델 정의
lgb_model = lgb.LGBMRegressor(
n_estimators=1000,
learning_rate=0.05,
max_depth=10,
random_state=42,
n_jobs=-1
)
# 모델 학습 - early stopping 및 학습 진행 상황 출력
lgb_model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
eval_metric='rmse', # 평가 메트릭 설정
callbacks=[
lgb.early_stopping(stopping_rounds=100), # early stopping 콜백
lgb.log_evaluation(50) # 50번마다 학습 로그 출력
]
)
# 예측
y_pred = lgb_model.predict(X_test)
# 모델 성능 평가 (RMSE)
rmse = mean_squared_error(y_test, y_pred, squared=False)
print(f"RMSE: {rmse}")
# 예측값이 연속형이므로 회귀 평가지표 사용
print("RMSE:", mean_squared_error(y_test, y_pred, squared=False)) # Root Mean Squared Error
print("MAE:", mean_absolute_error(y_test, y_pred)) # Mean Absolute Error
print("R² Score:", r2_score(y_test, y_pred)) # R^2 Score (결정 계수)
결과는 아래와 같다.
R 스퀘어 값이 0.8로 지나치게 높아 보인다.
3) 실제값과 예측 값 산점도를 그려본다면 아래와 같은 결과가 나타난다.
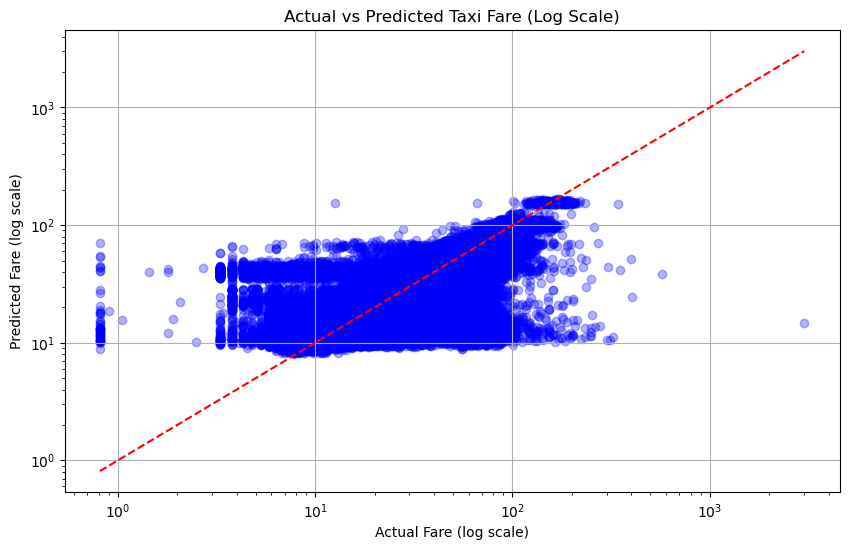
- 실제값과 예측값 간의 산점도를 기본적으로 한 번 보고, 로그변환을 하여 보고, 축범위를 제한하여 보았다. 대부분의 그래프에서 낮은 값에 대해 높은 정확도를 보여주고 있다.
D. 마무리
모델의 초기 분석에서는 충분한 인사이트를 도출하지 못했지만, 이를 통해 추가적인 분석 방향을 설정할 수 있었다. 특히 클러스터링을 통해 도출한 추천 승차 위치와 위도·경도 정보를 보면, 이 값들이 프로젝트의 목표 달성에 중요한 역할을 할 수 있었을 것이라는 생각이 든다. 그러나 분석 과정에서 데이터를 충분히 이해하지 못한 채 기계적으로 분석한 결과, 프로젝트를 중도에 마무리하게 된 것 같다. 앞으로는 고객의 하차 지점에서 다음 고객의 목적지를 예측해, 더 높은 수익을 낼 수 있는 고객을 어떻게 태울 수 있을지에 대한 분석을 진행하고자 한다. 택시 운행은 하나의 사이클로 볼 수 있다. 손님을 내려준 후 빈 차로 돌아오는 상황을 줄이지 않으면 수익에 손해가 발생한다. 따라서 빈 차로 도로를 달리는 시간을 최소화하고, 더 높은 수익을 낼 수 있는 고객의 목적지를 예측하는 모델을 구축하고 싶다. 이를 위해 고객의 목적지와 다음 승객의 예상 위치를 함께 고려한 최적 경로 예측 모델을 탐색하여 택시 기사의 운영 효율성을 향상시키는 방안을 마련할 계획이다.
해당 데이터는 전자 상거래 플랫폼의 소매 부문 판매 채널과 관련된 것이다. 가장 정확한 보고서를 작성하기 위해서는 수익과 이익을 지난달 및 전년도 같은 기간과 비교하여 효과적인 마케팅 전략을 수립하는 것이 중요하다. 또한, 이익을 기준으로 상위 성과 제품을 식별하고 이러한 제품에 대한 세부 분석을 진행해야 하며, 미래 개발을 위한 성장 가능성이 있는 제품도 함께 평가해야 한다.
해당 데이터는 orders, order_items, customers, payments, products 의 총 5개 개별 파일로 하나의 데이터로 만들어 사용할 예정이다. cleaned csv 파일이 있지만 어떤 기준으로 어떤 방식으로 정제되었는지 모르기 때문에 사용하지 않는다.
2. 칼럼 확인
orders
- order_id(PK): 주문의 고유 식별자, 이 테이블의 기본 키 역할 - customer_id: 고객의 고유 식별자 - order_status: 주문 상태. 예: 배송됨, 취소됨, 처리 중 등 - order_purchase_timestamp: 고객이 주문을 한 시점의 타임스탬프 - order_approved_at: 판매자가 주문을 승인한 시점의 타임스탬프 - order_delivered_timestamp: 고객 위치에 주문이 배송된 시점의 타임스탬프 - order_estimated_delivery_date: 주문할 때 고객에게 제공된 예상 배송 날짜
order_items
- order_id(PK): 주문의 고유 식별자 - order_item_id(PK): 각 주문 내 항목 번호. 이 컬럼과 함께 order_id가 이 테이블의 기본 키 역할 - product_id: 제품의 고유 식별자 - seller_id: 판매자의 고유 식별자 - price: 제품의 판매 가격 - shipping_charges: 제품의 배송에 관련된 비용
customers
- customer_id(PK): 고객의 고유 식별자, 이 테이블의 기본 키 역할 - customer_zip_code_prefix: 고객의 우편번호 - customer_city: 고객의 도시 - customer_state: 고객의 주
payments
- order_id: 주문의 고유 식별자, 이 테이블에서 이 컬럼은 중복될 수 있다 - payment_sequential: 주어진 주문에 대한 결제 순서 정보를 제공 - payment_type: 결제 유형 예: 신용카드, 직불카드 등 - payment_installments: 신용카드 결제 시 할부 회차 - payment_value: 거래 금액
products
- product_id: 각 제품의 고유 식별자, 이 테이블의 기본 키 역할 - product_category_name: 제품이 속한 카테고리 이름 - product_weight_g: 제품 무게 (그램) - product_length_cm: 제품 길이 (센티미터) - product_height_cm: 제품 높이 (센티미터) - product_width_cm: 제품 너비 (센티미터)
3. 데이터 하나의 파일로 합치기
customers_df = customers_df.drop_duplicates()
# orders_df와 customers_df를 customer_id를 기준으로 병합
merged_df = pd.merge(orders_df, customers_df, on='customer_id', how='left')
# merged_df와 order_items_df를 order_id를 기준으로 병합
merged_df = pd.merge(merged_df, order_items_df, on='order_id', how='left')
# merged_df와 payments_df를 order_id를 기준으로 병합
merged_df = pd.merge(merged_df, payments_df, on='order_id', how='left')
# merged_df와 products_df를 product_id를 기준으로 병합
final_df = pd.merge(merged_df, products_df, on='product_id', how='left')
# 결과를 CSV 파일로 저장
# final_df.to_csv("merged_data_final.csv", index=False)
merge_df = final_df
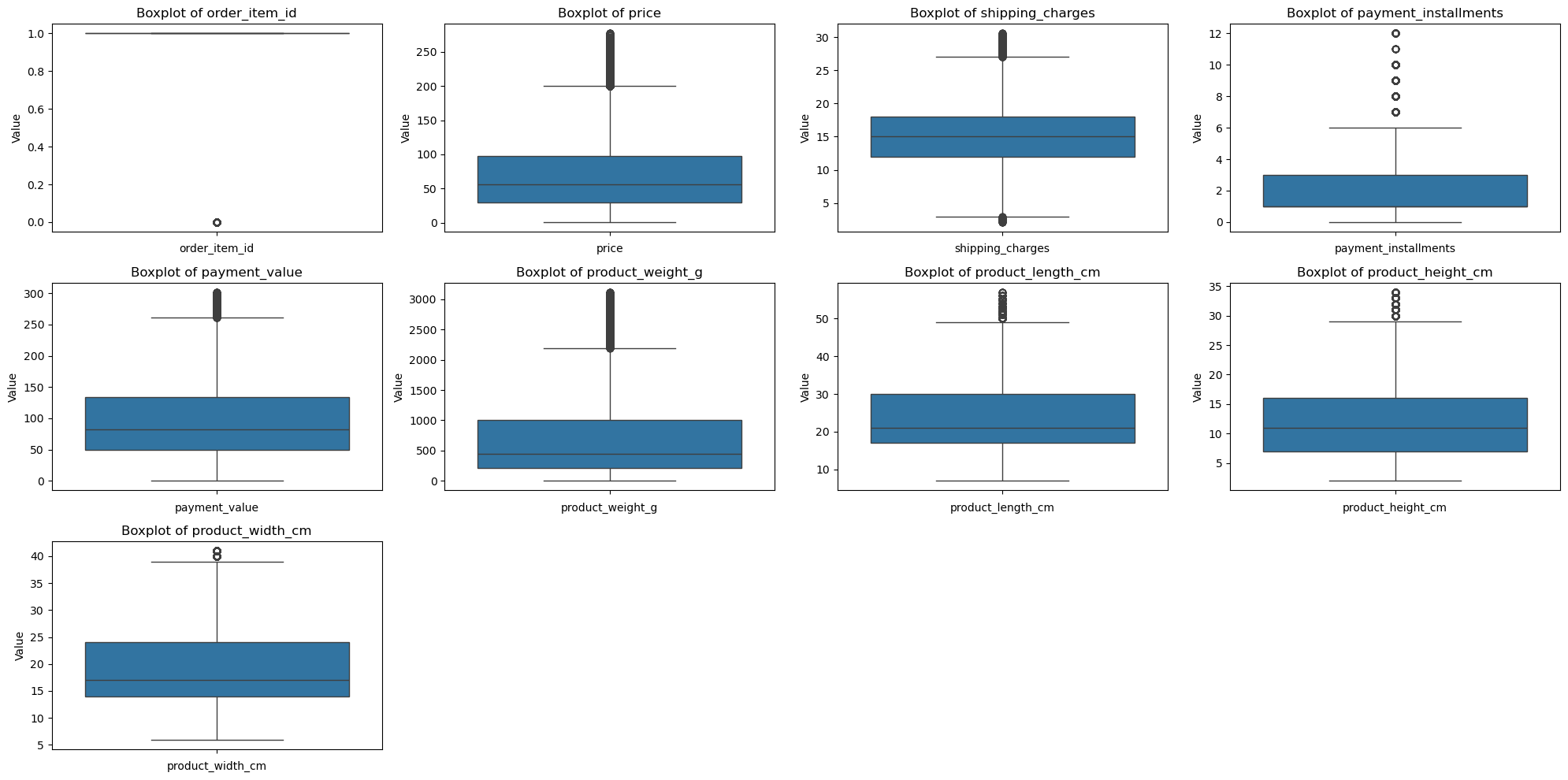
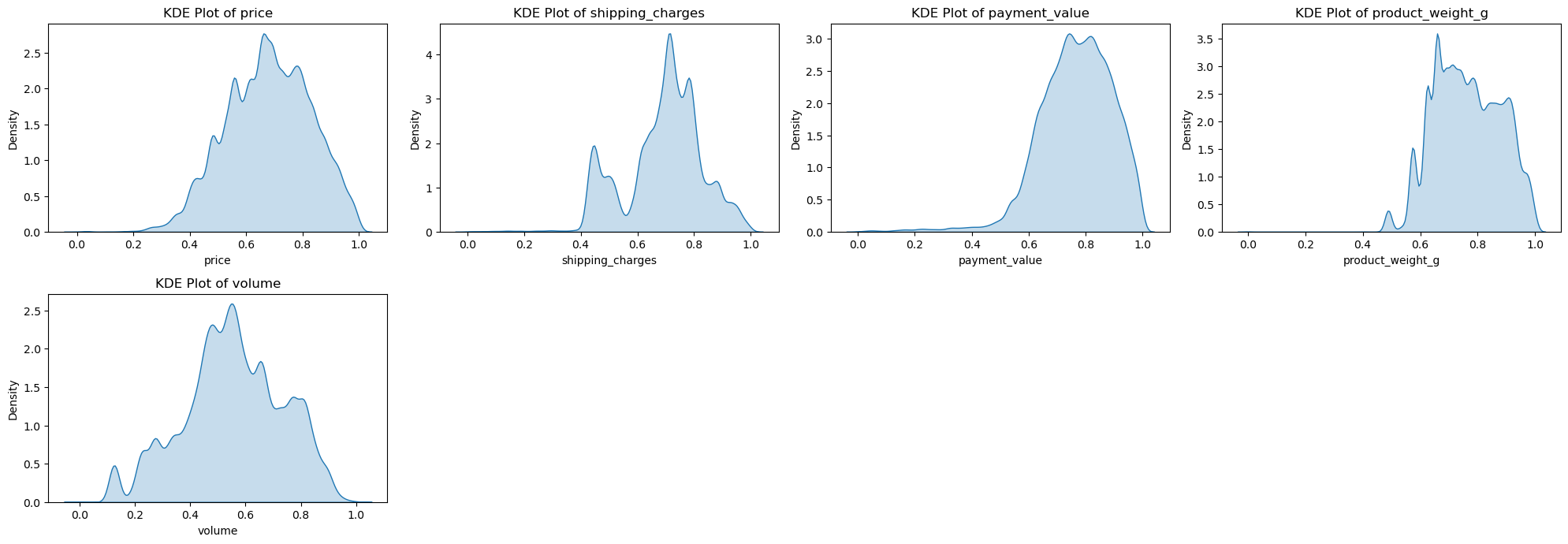
현재 수치형 변수가 오른쪽으로 꼬리가 긴 right-skewed 분포를 가지고 있다. 이에 로그 변환 방법으로 변수들을 조금 더 정규분포에 가깝게 만들어 비대칭성을 줄이고, 정규화(Nomalization)을 통해 데이터의 범위를 일정한 구간으로 변환하여 모델의 학습속도와 성능을 높이고자 한다.
해당 데이터는 범주형 변수가 많고, 해당 변수의 값들 또한 많기 때문에 One-Hot Encoding 방식은 적절하지 않을 것으로 사료된다. 이에 범주형 변수의 카테고리를 줄인 후에 Label-Encoding를 하고자 한다. 또한 위치 정보를 나타내는 칼럼들은 5개의 큰 구역으로 묶는 절차를 거친다.
# 범주형 변수들 처리 전 날짜 변수들의 dtype datetime으로 변경.
date_columns = ['order_purchase_timestamp', 'order_approved_at',
'order_delivered_timestamp', 'order_estimated_delivery_date']
for col in date_columns:
merged_df_cleaned[col] = pd.to_datetime(merged_df_cleaned[col])
merged_df_cleaned[date_columns].dtypes
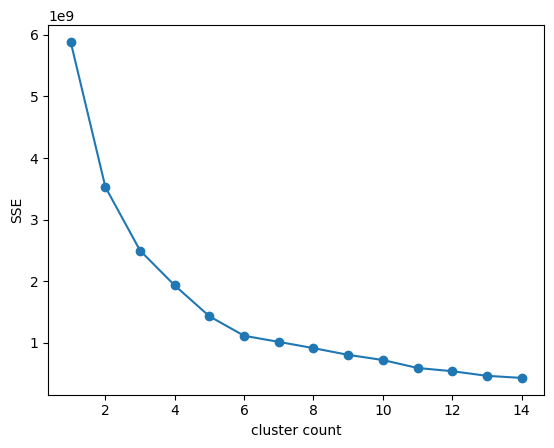
def elbow(df):
sse = []
for i in range(1,15):
km = KMeans(n_clusters= i, init='k-means++', random_state=42)
km.fit(df)
sse.append(km.inertia_)
plt.plot(range(1,15), sse, marker = 'o')
plt.xlabel('cluster count')
plt.ylabel('SSE')
plt.show()
elbow(cluster_1)
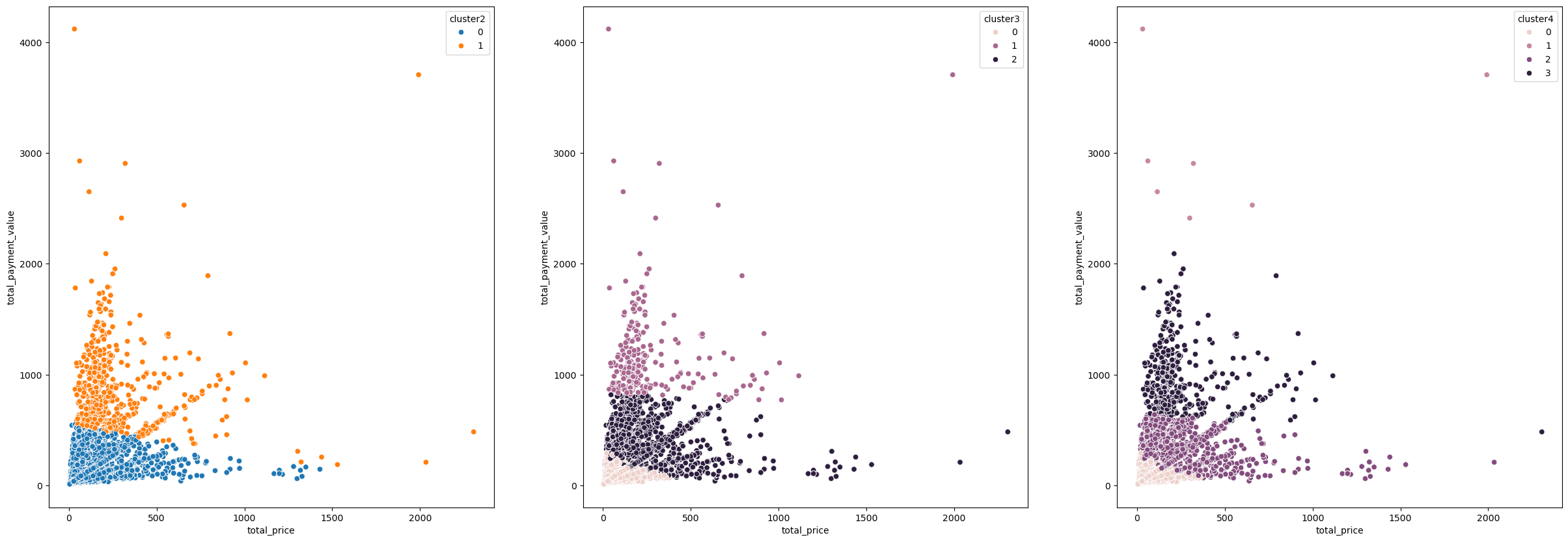
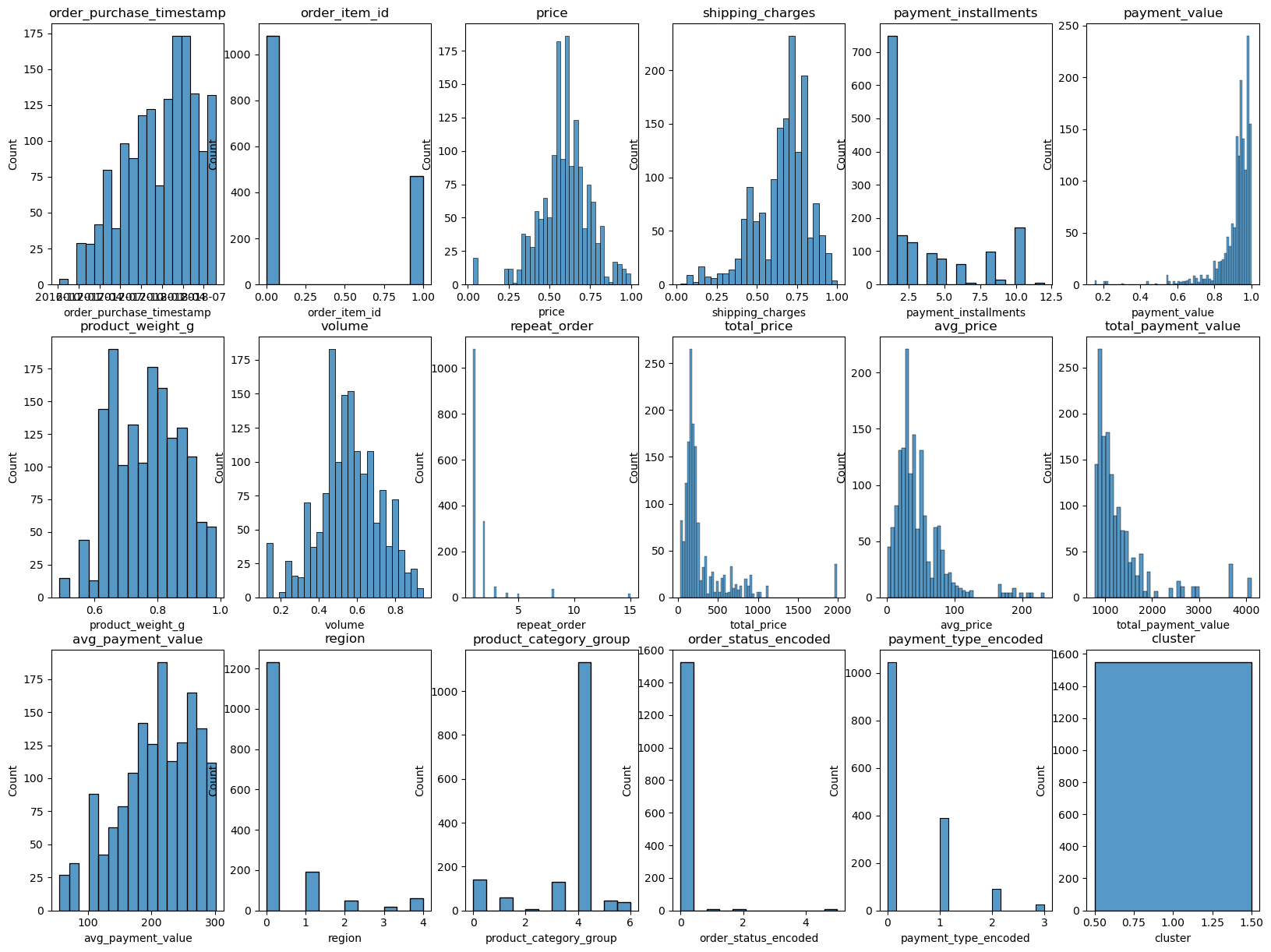
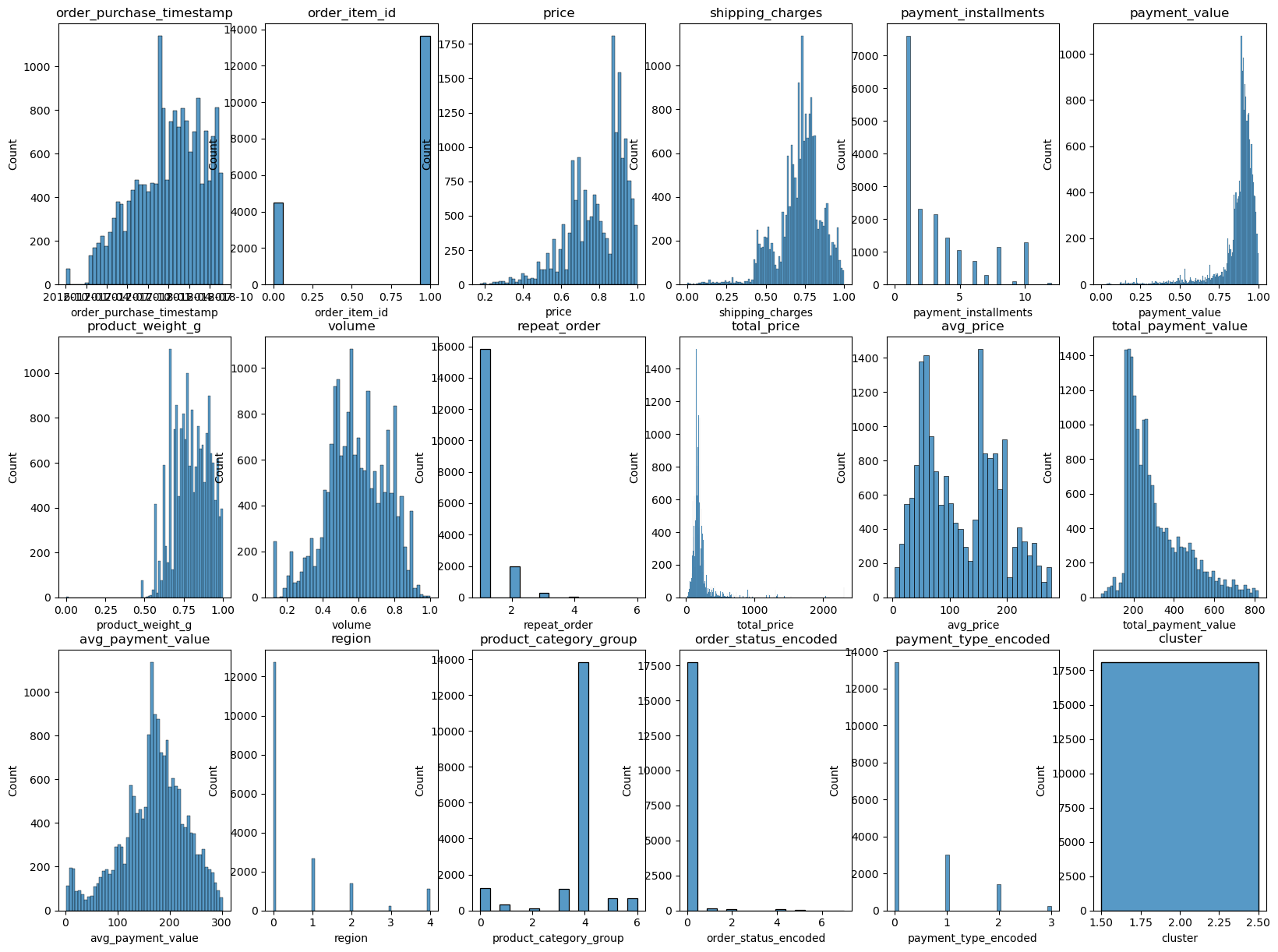
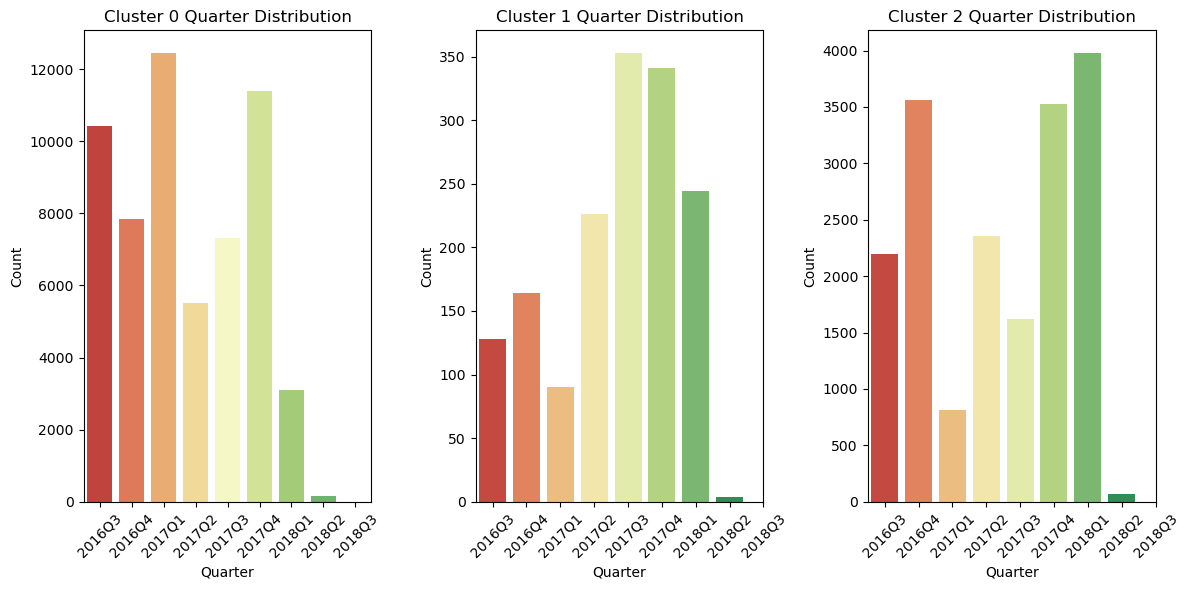
3. 군집 결과 해석
# 원본 자료는 살리기 위해 복사하기
merged_clu_df = merged_df_cleaned.copy()
# 클러스트 항목 설정
cluster_1 = merged_df_cleaned[['repeat_order','total_price', 'avg_price', 'total_payment_value', 'avg_payment_value']]
# 학습하기
# 군집 3개로 나누기
custoemr_kmeans3 = KMeans(n_clusters=3, init='k-means++', max_iter=300, random_state=42)
custoemr_kmeans3.fit(cluster_1)
# 군집된 결과 저장
merged_clu_df['cluster'] = custoemr_kmeans3.labels_
# 컬럼 지우는 함수
def del_cols(df):
del df['order_id']
del df['customer_id']
del df['seller_id']
del df['product_id']
del df['order_approved_at']
del df['order_delivered_timestamp']
del df['order_estimated_delivery_date']
# 군집 특성 확인하는 함수
def character_visual(df):
plt.figure(figsize=(20,20))
for i in range(len(df.columns)):
cols = list(df.columns)[i]
plt.subplot(4,6,i+1)
sns.histplot(df, x=cols, palette='RdYlGn')
plt.title(cols)
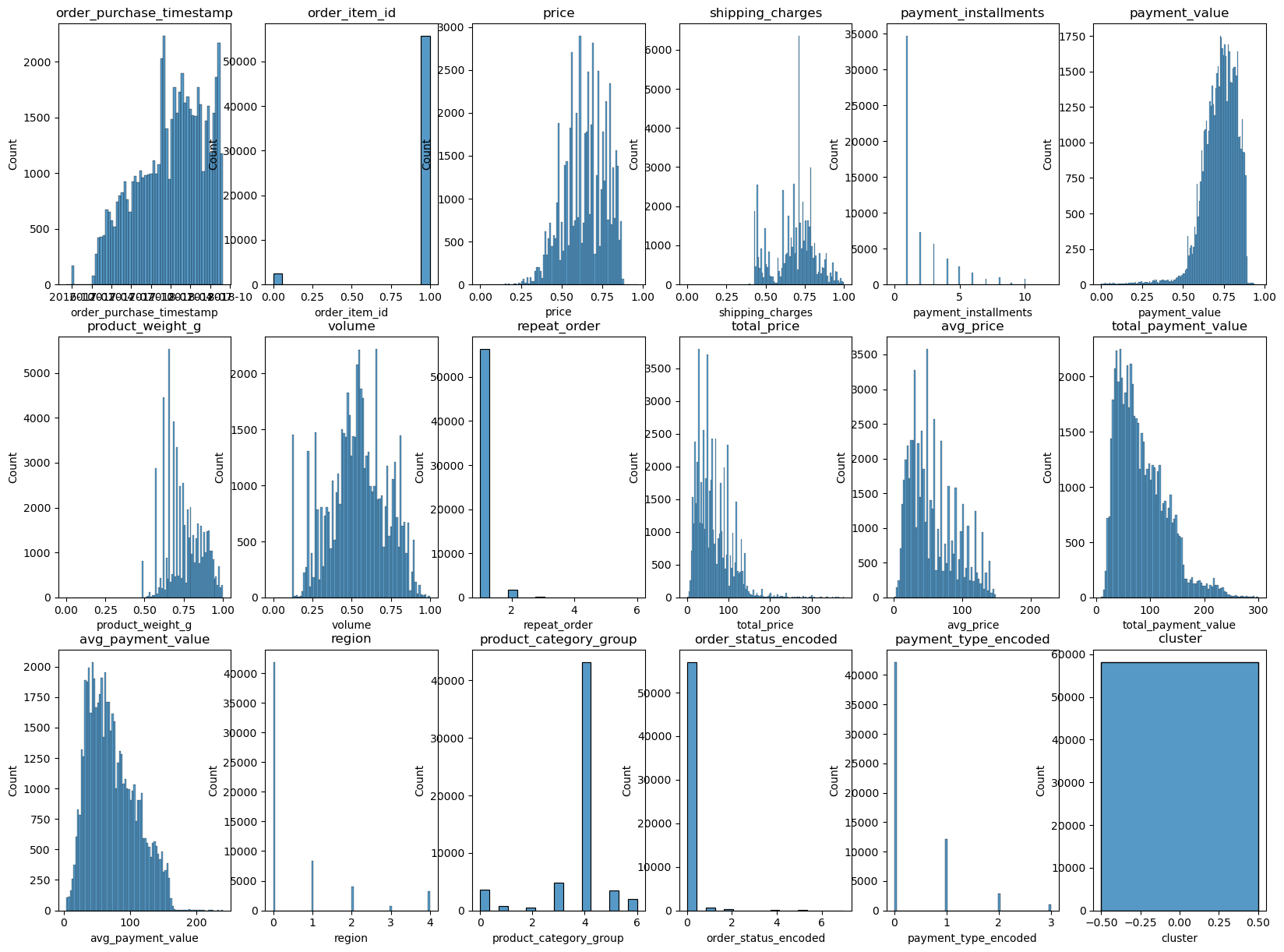
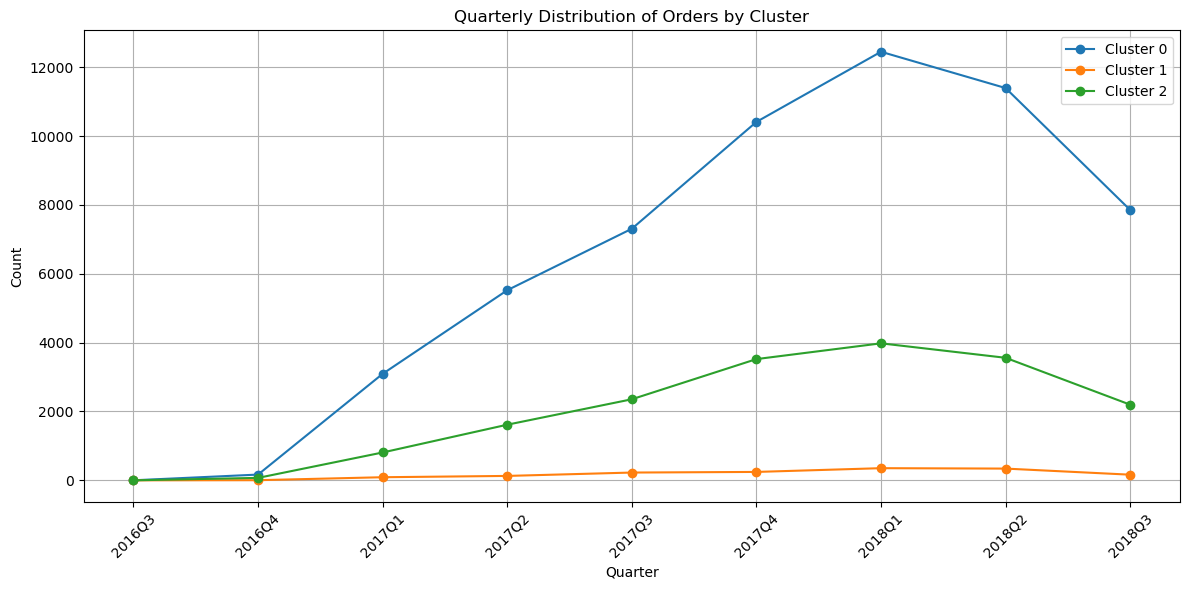
1) 1번 군집
# 1번 군집만 설정
merged_clu1_df = merged_clu_df[merged_clu_df['cluster'] == 0]
del_cols(merged_clu1_df)
character_visual(merged_clu1_df)