[TIL] 로지스틱 회귀분석(분류분석)
A. 금일 학습 내용
1. 타이타닉 데이터 확인하기
import pandas as pd
titaninc_df = pd.read_csv('D:/BootCamp/machine_learning/ML/titanic/train.csv')
titaninc_df.head(3)
titaninc_df.info()
titaninc_df.describe()
- 데이터 모양 확인하기

- 데이터 타입 및 결측치 등 정보 확인하기

- 타이타닉 데이터의 기술 통계 확인하기(수치형만 사용하기로 한다.)
2. 가설 세우기
- 정확도(Accuracy) = 맞춘 개수 / 전체 데이터
- 생존을 맞추고자 한다.
2-1. 첫 번째 예측
- 여성은 모두 살았을 것이고, 남성은 모두 죽었을 것이다 라고 가정한다면 아래와 같은 계산을 할 수 있다.
(233+468)/891*100- 값: 78.67564534231201
2-2. 두 번째 예측
- 가설: 비상 상황 특성 상 여성을 우선 배려하여 남성보다 많이 살아남음
- 수치형 변수: Age, SibSp, Parch, Fare
- 범주형 변수: Pclass, Sex, Cabin, Embarked
3. x변수 설정하기
- 로지스틱 선형회귀 모델을 사용할 예정이므로 수치형 변수인 Fare 값 1개만 x값으로 설정한다.
# x변수: Fare, y변수: Survived
X_1 = titaninc_df[['Fare']]
y_true = titaninc_df[['Survived']]
sns.histplot(titaninc_df, x='Fare')
sns.scatterplot(titaninc_df, x='Fare', y='Survived')
- 500이 넘어가는 수치가 있음을 알 수 있다.
- 해당 값을 어떻게 처리할지 고민해 보아야 한다.

from sklearn.linear_model import LogisticRegression
model_lor = LogisticRegression()
model_lor.fit(X_1, y_true)
4. 모델 분석하기
def get_att(x):
# x모델을 넣기
print('클래스 종류', x.classes_)
print('독립변수 갯수', x.n_features_in_)
print('들어간 독립변수(x)의 이름', x.feature_names_in_)
print('가중치',x.coef_)
print('바이어스',x.intercept_)
get_att(model_lor)
5. 모델의 정확도, 정밀도, 재현율 평가지표 확인하기 [머신러닝 분류모델 평가]
from sklearn.metrics import accuracy_score, f1_score
def get_metrics(true, pred):
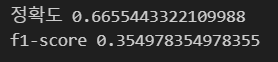
print('정확도',accuracy_score(true,pred))
print('f1-score',f1_score(true,pred))- accuracy_score 은 모델의 정확도를 평가하는 지표이다.
- f1-score 은 모델의 정밀도와 재현율의 기하평균 값으로, 모델의 정밀도와 재현율을 모두 고려한 평가 지표이다.
- f1-score 점수는 최소 0, 최대 1의 값을 가지고 높을 수록 좋은 성능을 나타낸다.
6. 데이터 넣어 예측값 확인하기
y_pred_1 = model_lor.predict(X_1)
get_metrics(y_true, y_pred_1)- predict 메소드는 학습한 데이터를 바탕으로 새로운 데이터가 입력되면 그에 맞는 결과를 예측한다.
model_lor.predict_proba(X_1)
- predict_proba 메소드는 확률을 반환한다.
- 각 클래스에 대해 [살아남을 확률, 죽을 확률] 값을 array 형식으로 나타낸다.
B. 마무리
- 간단한로지스틱 회귀분석에 대해 알아보았다.
- 다음은 이상치, 결측치 처리 및 범주형 데이터를 인코딩하는 등 데이터 전처리 등의 방법을 이용하는 좀 더 복잡한 머신러닝 모델을 보고자 한다.